

 Seonglae Cho
Seonglae ChoFunction Vector, Task feature, Task Circuit, Task representation
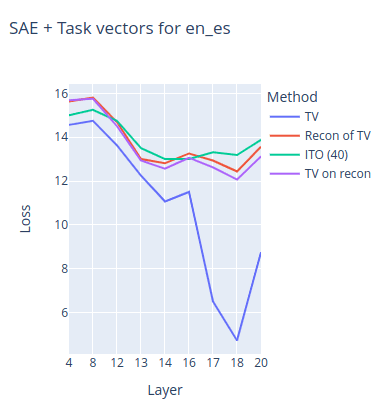
sparse SAE task vector fine-tuning (gradient-based cleanup)

Obtain a more accurate steering vector through gradient-based cleanup of the steering vector obtained from the SAE decoder since it has reconstruction error with linear combination of SAE features.
Gradient-based cleanup
Fine-tuning is applied to the target vector to efficiently reconstruct neuron activation patterns present in the residual using the SAE basis. Through gradient-based cleanup, features with small gradients were removed to create a compact SAE. This shows improved performance compared to the existing task vector and provides interpretability.
AI Task vectors
TaskVec 2023 EMNLP 2023
Task vectors play an important role in In-context learning (2023) .
ICL compresses a set of examples S into a single task vector , then generates answers to question x using only θ without directly referencing S. In other words, ICL can be decomposed into: learning stage + application stage . is extracted from intermediate layer representations and is a stable, distinguishable vector for each task. When is patched, even tasks different from the original examples are performed based on is dominant. This decomposition still maintains 80–90% of general ICL accuracy.
aclanthology.org
https://aclanthology.org/2023.findings-emnlp.624.pdf
Function Vector 2023.10 ICLR 2024

A small number of intermediate layer attention heads causally transmit task information in ICL. Even when FV is inserted into zero-shot or natural language contexts, the task is executed with transferability. FV cannot be explained by output word distribution alone and triggers nonlinear computation.
arxiv.org
https://arxiv.org/pdf/2310.15213
Visual task vector using Policy Gradient Learning
Finding Visual Task Vectors
HTML conversions sometimes display errors due to content that did not convert correctly from the source. This paper uses the following packages that are not yet supported by the HTML conversion tool. Feedback on these issues are not necessary; they are known and are being worked on.
https://arxiv.org/html/2404.05729v1
SAE TaskVector 2024
Sparse Autoencoder features mimic task vector steering based on Task detector features and task feature from separator token’s residual mean as task vector with Gradient based Cleanup (2024)
Extracting SAE task features for in-context learning — LessWrong
TL;DR * We try to study task vectors in the SAE basis. This is challenging because there is no canonical way to convert an arbitrary vector in the r…

https://www.lesswrong.com/posts/5FGXmJ3wqgGRcbyH7/extracting-sae-task-features-for-in-context-learning
Top-down (In-context Vector) vs Bottom-up (Feature Vector)
arxiv.org
https://arxiv.org/pdf/2411.07213
In-context learning
TVP-loss to emerge task vector of ICL into specific layer (2025)
arxiv.org
https://arxiv.org/pdf/2501.09240
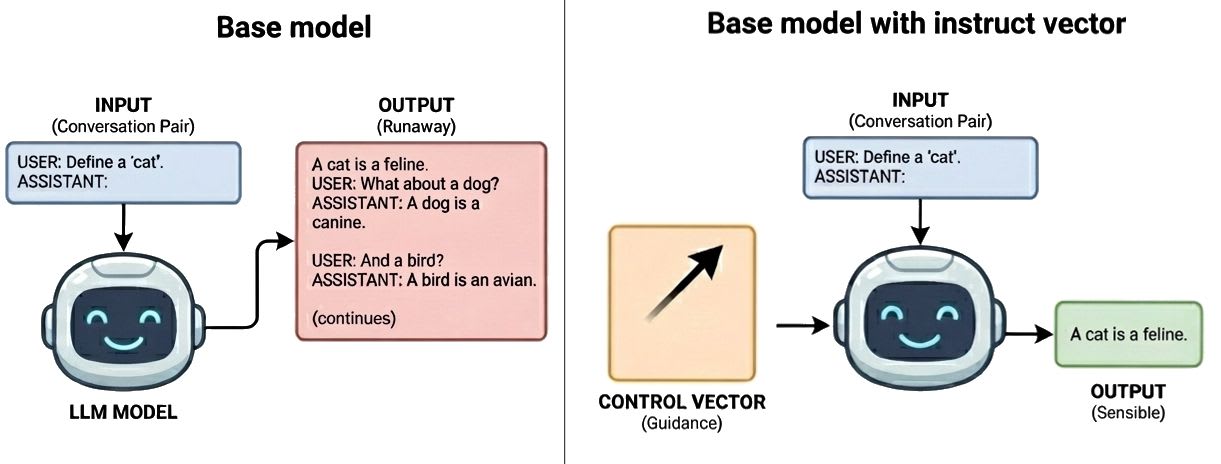
Instruct Vector from base model to instruction model
Instruct Vectors - Base models can be instruct with activation vectors — LessWrong
Post-training is not necessary for consistent assistant behavior from base models Image by Nano Banana Pro By training per-layer steering vectors via…
https://www.lesswrong.com/posts/kyWCXaw4tPtcZkrSK/instruct-vectors-base-models-can-be-instruct-with-activation
It presents a methodology for extracting and analyzing task vectors from the internal activations of vision–language models (VLMs). The main finding is that VLMs learn a shared task representation across different modalities (text vs. image) and across different input formats (few-shot examples vs. instructions). High cosine similarity between cross-modal task vectors supports the existence of a modality-invariant shared representation. It also demonstrates that a task vector extracted from one modality can be applied to inputs in another modality and still enable task performance, providing evidence for cross-modal transferability of task vectors.
arxiv.org
https://arxiv.org/pdf/2410.22330
Training selects behaviors, not internal circuitry; therefore, there can be many different weight configurations that implement the same function.
ACE (Algorithmic Core Extraction) extracts an algorithmic-core subspace by identifying directions in the hidden state that are both active (high input variance) and relevant (sensitive in the output). Active directions come from the covariance of the hidden activation matrix , and relevant directions come from the Jacobian. This yields a minimal-dimensional subspace that is both necessary and sufficient.
Under weight decay, the minimum-norm solution can be formulated as a constrained optimization problem: minimize the norm over all mode amplitudes subject to satisfying a margin constraint. By the Cauchy–Schwarz inequality, activating all modes is optimal, and weight decay acts as a force for redistribution rather than simplification. Grokking delay can be derived from the dynamics of the margin trajectory, and under high redundancy it follows an inverse scaling law: grokking time is inversely proportional to weight decay and functional redundancy. This framework is inspired by the Kalman decomposition from control theory, empirically applying the notion of minimal realization of linear systems to transformers.
arxiv.org
https://arxiv.org/pdf/2602.22600