

 Seonglae Cho
Seonglae ChoChristopher Olah
Ilya Sutskever of Anthropic AI, Future Novel Laureate
How this weight correspond to this algorithm.
Mechanistic Interpretability explained | Chris Olah and Lex Fridman
Lex Fridman Podcast full episode: https://www.youtube.com/watch?v=ugvHCXCOmm4
Thank you for listening ❤ Check out our sponsors: https://lexfridman.com/sponsors/cv8247-sb
See below for guest bio, links, and to give feedback, submit questions, contact Lex, etc.
*GUEST BIO:*
Dario Amodei is the CEO of Anthropic, the company that created Claude. Amanda Askell is an AI researcher working on Claude's character and personality. Chris Olah is an AI researcher working on mechanistic interpretability.
*CONTACT LEX:*
*Feedback* - give feedback to Lex: https://lexfridman.com/survey
*AMA* - submit questions, videos or call-in: https://lexfridman.com/ama
*Hiring* - join our team: https://lexfridman.com/hiring
*Other* - other ways to get in touch: https://lexfridman.com/contact
*EPISODE LINKS:*
Claude: https://claude.ai
Anthropic's X: https://x.com/AnthropicAI
Anthropic's Website: https://anthropic.com
Dario's X: https://x.com/DarioAmodei
Dario's Website: https://darioamodei.com
Machines of Loving Grace (Essay): https://darioamodei.com/machines-of-loving-grace
Chris's X: https://x.com/ch402
Chris's Blog: https://colah.github.io
Amanda's X: https://x.com/AmandaAskell
Amanda's Website: https://askell.io
*SPONSORS:*
To support this podcast, check out our sponsors & get discounts:
*Encord:* AI tooling for annotation & data management.
Go to https://lexfridman.com/s/encord-cv8247-sb
*Notion:* Note-taking and team collaboration.
Go to https://lexfridman.com/s/notion-cv8247-sb
*Shopify:* Sell stuff online.
Go to https://lexfridman.com/s/shopify-cv8247-sb
*BetterHelp:* Online therapy and counseling.
Go to https://lexfridman.com/s/betterhelp-cv8247-sb
*LMNT:* Zero-sugar electrolyte drink mix.
Go to https://lexfridman.com/s/lmnt-cv8247-sb
*PODCAST LINKS:*
- Podcast Website: https://lexfridman.com/podcast
- Apple Podcasts: https://apple.co/2lwqZIr
- Spotify: https://spoti.fi/2nEwCF8
- RSS: https://lexfridman.com/feed/podcast/
- Podcast Playlist: https://www.youtube.com/playlist?list=PLrAXtmErZgOdP_8GztsuKi9nrraNbKKp4
- Clips Channel: https://www.youtube.com/lexclips
*SOCIAL LINKS:*
- X: https://x.com/lexfridman
- Instagram: https://instagram.com/lexfridman
- TikTok: https://tiktok.com/@lexfridman
- LinkedIn: https://linkedin.com/in/lexfridman
- Facebook: https://facebook.com/lexfridman
- Patreon: https://patreon.com/lexfridman
- Telegram: https://t.me/lexfridman
- Reddit: https://reddit.com/r/lexfridman

https://www.youtube.com/watch?v=riniamTdUSo

CV
colah.github.io
https://colah.github.io/cv.pdf
Home - colah's blog
Writing rough notes allows me share more content, since polishing takes lots of time.
While I hope it's useful,
it's
likely lower quality and less carefully considered than my usual articles.
https://colah.github.io/
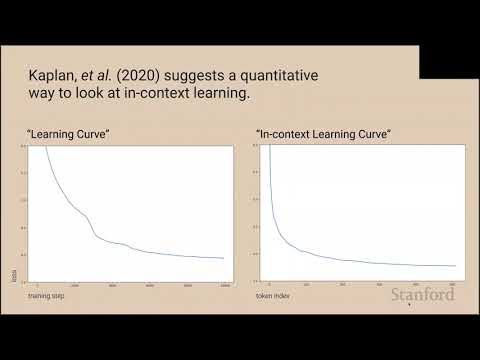
Stanford CS25: V1 I Transformer Circuits, Induction Heads, In-Context Learning
"Neural network parameters can be thought of as compiled computer programs. Somehow, they encode sophisticated algorithms, capable of things no human knows how to write a computer program to do. Mechanistic interpretability seeks to reverse engineer neural networks into human understandable algorithms. Previous work has tended to focus on vision models; this talk will explore how we might reverse engineer transformer language models.
In particular, we'll focus on what we call ""induction head circuits"", a mechanism that appears to be significantly responsible for in-context learning. Using a pair of attention heads, these circuits allow models to repeat text from earlier in the context, translate text seen earlier, mimic functions from examples earlier in the context, and much more. The discovery of induction heads in the learning process appears to drive a sharp phase change, creating a bump in the loss curve, pivoting models learning trajectories, and greatly increasing their capacity for in-context learning, in the span of just a few hundred training steps."
Chris Olah is a co-founder of Anthropic, an AI company focused on the safety of large models, where he leads Anthropic's interpretability efforts. Previously, Chris led OpenAI's interpretability team, and was a researcher at Google Brain. Chris' work includes the Circuits project, his blog (especially his tutorial on LSTMs), the Distill journal, and DeepDream.
View the entire CS25 Transformers United playlist: https://www.youtube.com/playlist?list=PLoROMvodv4rNiJRchCzutFw5ItR_Z27CM

https://www.youtube.com/watch?v=pC4zRb_5noQ
Building Anthropic | A conversation with our co-founders
The co-founders of Anthropic discuss the past, present, and future of Anthropic. From left to right: Chris Olah, Jack Clark, Daniela Amodei, Sam McCandlish, Tom Brown, Dario Amodei, and Jared Kaplan.
Links and further reading:
Anthropic's Responsible Scaling Policy (RSP): https://www.anthropic.com/news/announcing-our-updated-responsible-scaling-policy
Machines of Loving Grace: https://darioamodei.com/machines-of-loving-grace
Work with us: https://anthropic.com/careers
Claude: https://claude.com
00:00 Why work on AI?
02:08 Scaling breakthroughs
03:30 Early days of AI
10:57 Sentiment shifting
18:30 The Responsible Scaling Policy
30:42 Founding story
32:45 Building a culture of trust
39:08 Racing to the top
43:43 Looking to the future

https://www.youtube.com/watch?v=om2lIWXLLN4
