

 Seonglae Cho
Seonglae ChoHow To Become A Mechanistic Interpretability Researcher — LessWrong
Note: If you’ll forgive the shameless self-promotion, applications for my MATS stream are open until Sept 12. I help people write a mech interp paper…

https://www.lesswrong.com/posts/jP9KDyMkchuv6tHwm/how-to-become-a-mechanistic-interpretability-researcher

ARENA tutorial for everyone
Home
This GitHub repo hosts the exercises and Streamlit pages for the ARENA 3.0 program.

https://arena3-chapter1-transformer-interp.streamlit.app/

AI researcher starting for interpretability
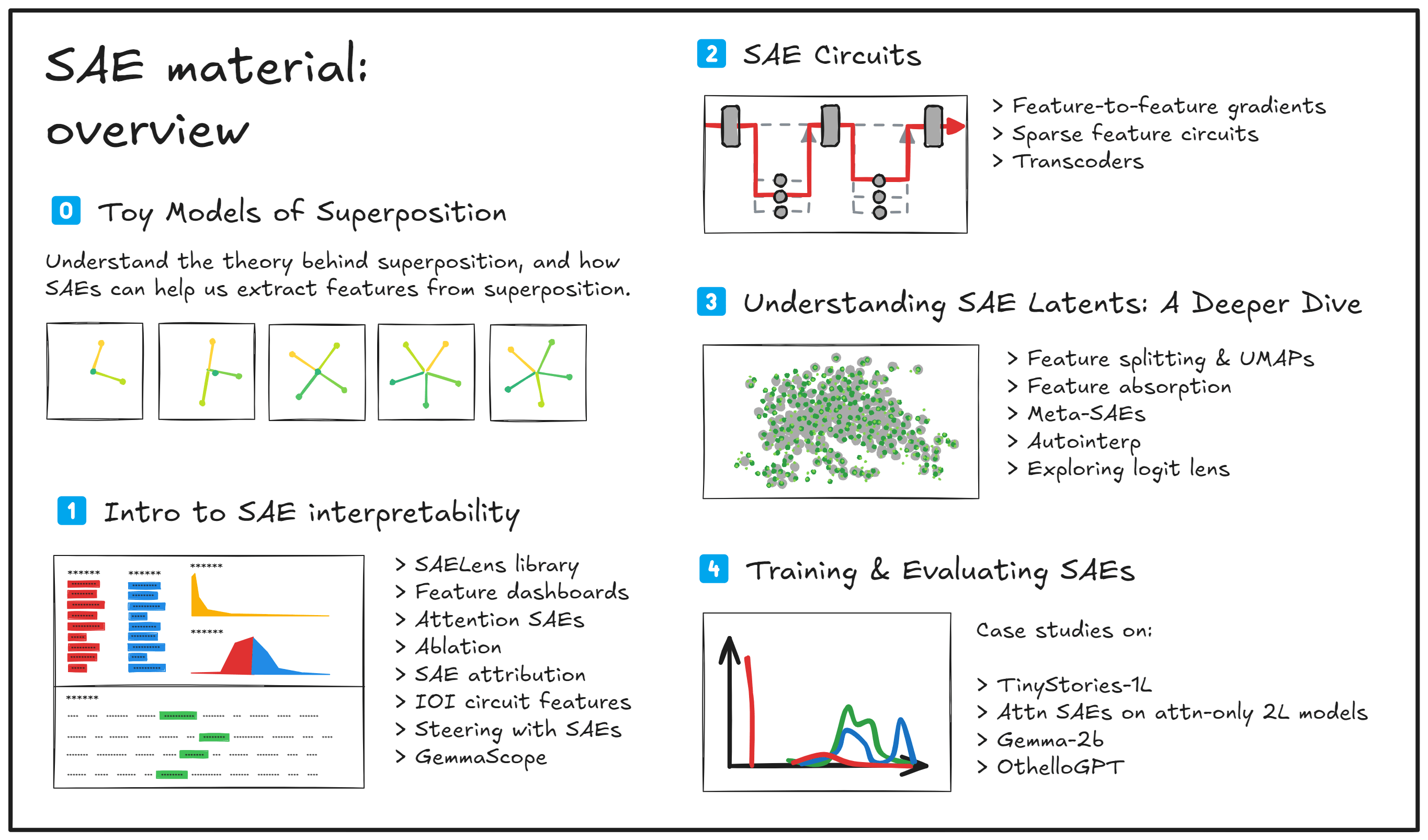
Interpretability with Sparse Autoencoders (Colab exercises) — LessWrong
Update (13th October 2024) - these exercises have been significantly expanded on. Now there are 2 exercise sets: the first one dives deeply into theo…
https://www.lesswrong.com/posts/LnHowHgmrMbWtpkxx/intro-to-superposition-and-sparse-autoencoders-colab
Reading list
An Extremely Opinionated Annotated List of My Favourite Mechanistic Interpretability Papers v2 — AI Alignment Forum
This post represents my personal hot takes, not the opinions of my team or employer. This is a massively updated version of a similar list I made two…

https://www.alignmentforum.org/posts/NfFST5Mio7BCAQHPA/an-extremely-opinionated-annotated-list-of-my-favourite

Chris Olah
Mechanistic Interpretability, Variables, and the Importance of Interpretable Bases
Mechanistic interpretability seeks to reverse engineer neural networks, similar to how one might reverse engineer a compiled binary computer program. After all, neural network parameters are in some sense a binary computer program which runs on one of the exotic virtual machines we call a neural network architecture.
https://transformer-circuits.pub/2022/mech-interp-essay/index.html
Neel Nanda
The field of study of reverse engineering neural networks from the learned weights down to human-interpretable algorithms. Analogous to reverse engineering a compiled program binary back to source code.
A Comprehensive Mechanistic Interpretability Explainer & Glossary - Dynalist
Dynalist lets you organize your ideas and tasks in simple lists. It's powerful, yet easy to use. Try the live demo now, no need to sign up.
https://dynalist.io/d/n2ZWtnoYHrU1s4vnFSAQ519J#z=eL6tFQqNwd4LbYlO1DVIen8K
Concrete Steps to Get Started in Transformer Mechanistic Interpretability — Neel Nanda
Disclaimer : This post mostly links to resources I've made. I feel somewhat bad about this, sorry! Transformer MI is a pretty young and small field and there just aren't many people making educational resources tailored to it. Some links are to collations of other people's work, and I
https://www.neelnanda.io/mechanistic-interpretability/getting-started
history
The Story of Mech Interp
This is a talk I gave to my MATS scholars, with a stylised history of the field of mechanistic interpretability, as I see it (with a focus on the areas I've personally worked in, rather than claiming to be fully comprehensive). We stop at the start of sparse autoencoders, that part is coming soon!
00:00:00 Introduction & Scope
00:02:45 Three Core Themes
00:06:03 Grounding Research & Linearity
00:15:00 Early Vision Models
00:19:26 Feature Visualization Era
00:25:24 Interactive Tools & Adversarial Examples
00:32:00 Circuit Analysis in CNNs
00:37:42 Shift to Transformers
00:42:14 Grokking & Modular Addition
00:47:24 Causal Interventions Introduced
00:52:06 Activation Patching Method
00:58:29 Factual Recall Messiness
01:08:21 IOI Circuit Findings
01:13:20 Copy Suppression & Self-Correction
01:18:46 Backup Heads Problem
01:22:21 Superposition Challenge
01:28:00 Toy Models & Current Outlook
01:37:09 Q&A: Circuits Research Today
01:39:36 Q&A: Universality Across Models
01:48:18 Q&A: Adversarial Examples & Baselines
01:57:59 Q&A: Random Controls Matter
02:02:35 Q&A: Jailbreaks & SAE Analysis
02:08:14 Q&A: Probes & Robustness

https://www.youtube.com/watch?v=kkfLHmujzO8

reaserch
Tips for Empirical Alignment Research — LessWrong
TLDR: I’ve collected some tips for research that I’ve given to other people and/or used myself, which have sped things up and helped put people in th…
https://www.lesswrong.com/posts/dZFpEdKyb9Bf4xYn7/tips-for-empirical-alignment-research
Youtubers
Goodfire
Our mission is to advance humanity's understanding of AI by examining the inner workings of advanced AI models (or "AI Interpretability"). As an applied research lab, we bridge the gap between theoretical science and practical applications of interpretability to build safer and more reliable AI models.

https://www.youtube.com/@GoodfireAI

Principles of Intelligence
Principles of Intelligence (PrincInt) aims to facilitate knowledge transfer with the goal of building human-aligned AI systems. Our Fellowship (PIBBSS Fellowship) aims to draw experts from different fields and help them work on the most pressing issues in AI Risks. This channel is the repository for recorded talks, speaker events, and other materials relevant to PrincInt and PIBBSS-style research. You can learn more about us at www.princint.ai
https://www.youtube.com/@PrincInt/videos

inside llms
Inside LLMs | Mechanisms
The mechanisms, circuits, representations, algebraic structure, failure modes, all of it.
https://inside-llms.gitbook.io/mechanisms