

 Seonglae Cho
Seonglae ChoThe architecture has separate for each layer while sharing only the latent dictionary for scaling, where : source layer-specific encoder, : target layer-specific decoder, : reconstructed layer activation from source latent.
Each input-output layer pair has its own encoder-decoder weight pair. Unlike cross-layer transcoders (Circuit Tracing), encoders are not shared; instead, layers share the same latent space, achieved through loss-based approximation.
This is solved through alignment via co-training, where an alignment loss is added during training to force the latents to match, causing them to converge to a shared latent space.

The original purpose is cross-layer mapping and feature alignment, but it can be used for various purposes such as model diffing and scaling transfer
Decoder sparsity loss
Crosscoders
2025 findings on analysis
For some feature learned by the crosscoder, the decoder writes much more strongly into one model than the other. Features that are exclusive to a single model also tend to be systematically more polysemantic and activate more densely than shared features, which the authors argue comes from competition over limited feature capacity. They support this with toy-model experiments: when the number of learnable features is much larger than the number of ground-truth features, the density gap disappears; but when it is comparable or smaller, exclusive features show roughly an order-of-magnitude higher activation frequency. The key driver is the crosscoder objective.
Insights on Crosscoder Model Diffing
In this update, we investigate an unexpected phenomenon in crosscoder model diffing : features that are exclusive to one model tend to be more polysemantic and dense in their activations, making them difficult to interpret. Through experiments with toy models, we show that this likely emerges from competition for limited feature capacity – since shared features can explain neuron activation patterns in both models, exclusive features must encode more information to justify their allocation. We propose a mitigation strategy which introduces a small set of designated shared features with a reduced sparsity penalty, rendering the exclusive features more interpretable and monosemantic. When applied to real models, this approach successfully isolates interpretable features that capture expected differences in behavior between models considered.
https://transformer-circuits.pub/2025/crosscoder-diffing-update/index.html
CrossCoder (2024)
with Cross fine-tuning model & scaling transferability by diffing within same architecture
Sparse Crosscoders for Cross-Layer Features and Model Diffing
This note will cover some theoretical examples motivating crosscoders, and then present preliminary experiments applying them to cross-layer superposition and model diffing. We also briefly discuss the theory of how crosscoders might simplify circuit analysis, but leave results on this for a future update.
https://transformer-circuits.pub/2024/crosscoders/index.html
Open Source Replication of Anthropic’s Crosscoder paper for model-diffing — LessWrong
Intro Anthropic recently released an exciting mini-paper on crosscoders (Lindsey et al.). In this post, we open source a model-diffing crosscoder tra…

https://www.lesswrong.com/posts/srt6JXsRMtmqAJavD/open-source-replication-of-anthropic-s-crosscoder-paper-for
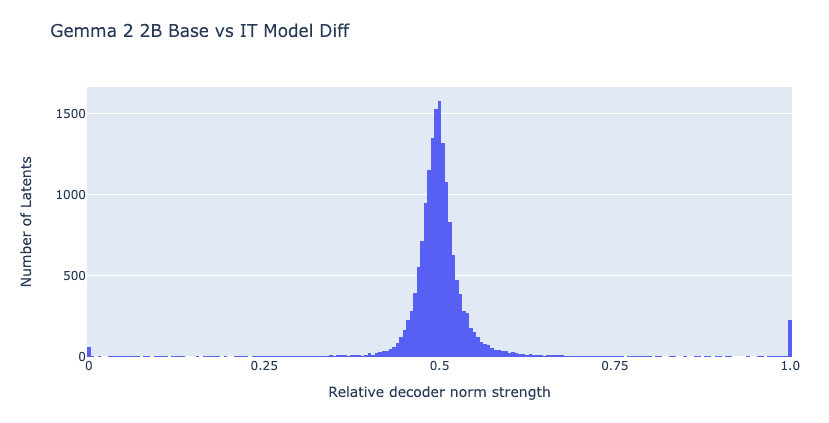
BatchTopK crosscoder to prevent Complete Shrinkage and Latent Decoupling for chat model
Robustly identifying concepts introduced during chat fine-tuning...
Model diffing is the study of how fine-tuning changes a model's representations and internal algorithms. Many behaviours of interest are introduced during fine-tuning, and model diffing offers a...
https://arxiv.org/abs/2504.02922
Using Crosscoder for chat Model Diffing reveals issues with traditional L1 sparsity approaches: many "chat-specific features" are falsely identified because they are actually existing concepts that shrink to zero in one model during training. Most chat-exclusive latents are training artifacts rather than genuine new capabilities.
Complete Shrinkage → A shared concept where one model's decoder shrinks to zero. Latent Decoupling → The same concept is represented by different latent combinations in two models.
Using Top-K (L0-style) sparsity instead of L1 reduces false positives and retains only alignment-related features. Chat tuning effects are primarily not about capabilities themselves, but rather: safety/refusal mechanisms, dialogue format processing, response length and summarization controls, and template token-based control. In other words, it acts more like a shallow layer that steers existing capabilities.
arxiv.org
https://arxiv.org/pdf/2504.02922