Seonglae Cho
Seonglae ChoDeceptive
ICLR 2025 oral
Shallow safety alignment & deep safety alignment
Safety Alignment Should be Made More Than Just a Few Tokens Deep
The safety alignment of current Large Language Models (LLMs) is vulnerable. Simple attacks, or even benign fine-tuning, can jailbreak aligned models. We note that many of these vulnerabilities are...
https://openreview.net/forum?id=6Mxhg9PtDE
arxiv.org
https://arxiv.org/pdf/2406.05946
There are cases where Chain of Thought (CoT) reasoning does not faithfully reflect the actual internal reasoning process - that is, there exists an inconsistency between the explicitly expressed reasoning process and the internal mechanism that actually derives the conclusion.
arxiv.org
https://arxiv.org/pdf/2503.08679
High level Conceptual
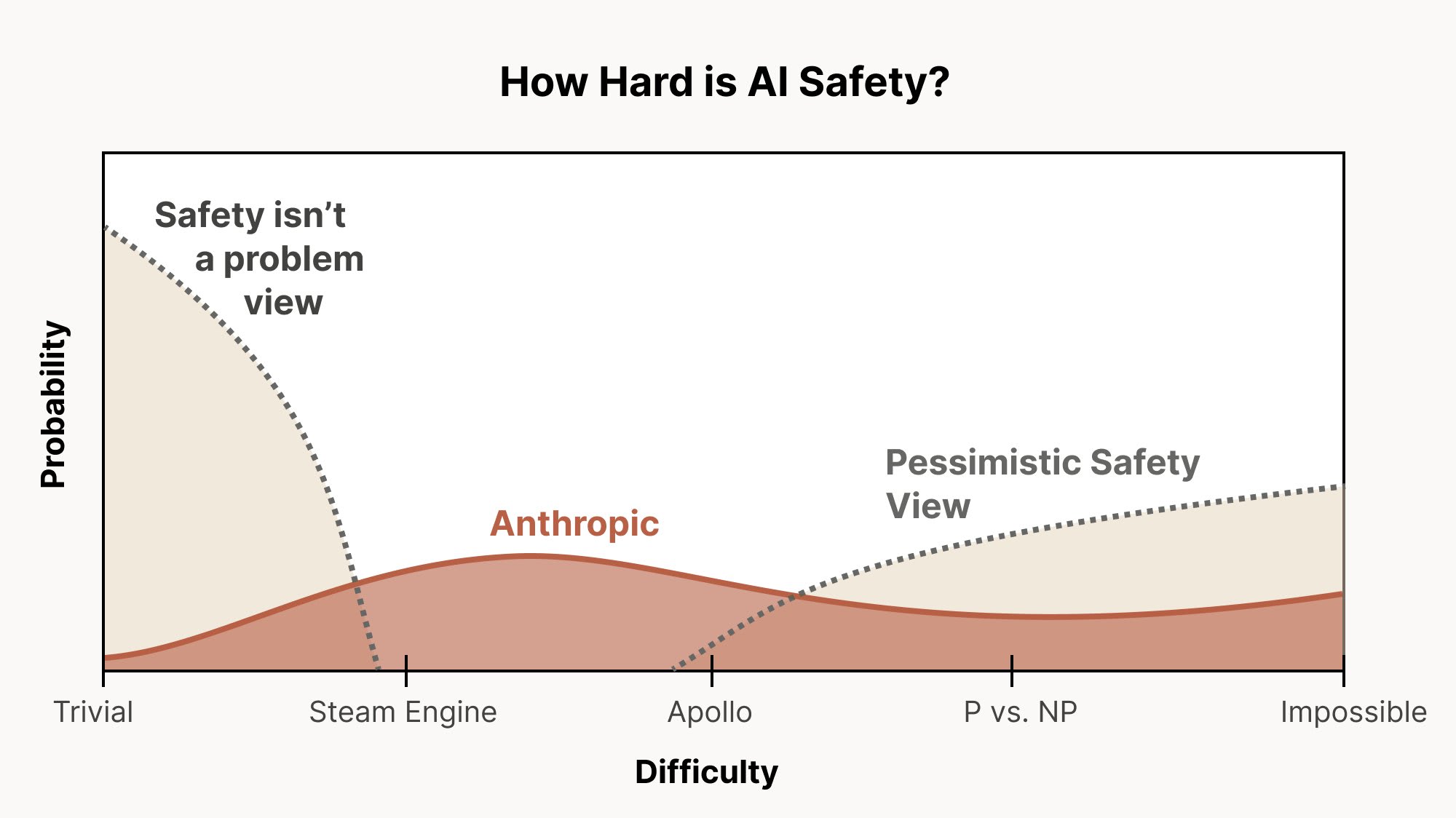
Alignment remains a hard, unsolved problem — LessWrong
This is a public adaptation of a document I wrote for an internal Anthropic audience about a month ago. Thanks to (in alphabetical order) Joshua Bats…

https://www.lesswrong.com/posts/epjuxGnSPof3GnMSL/alignment-remains-a-hard-unsolved-problem