

 Seonglae Cho
Seonglae ChoDeep sparse autoencoders yield interpretable features too — LessWrong
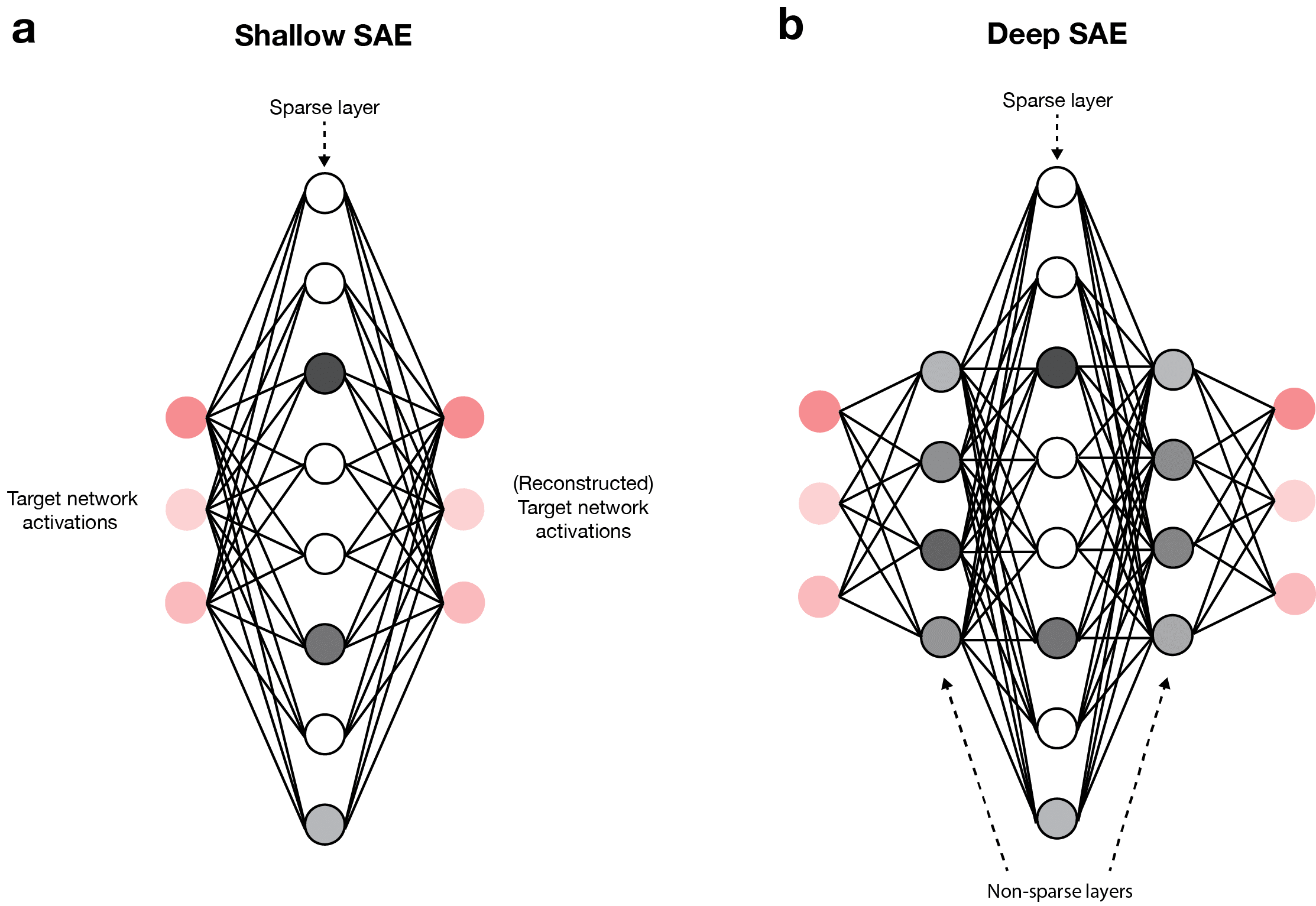
I sandwich the sparse layer in a sparse autoencoder (SAE) between non-sparse lower-dimensional layers and refer to this as a deep SAE.

https://www.lesswrong.com/posts/tLCBJn3NcSNzi5xng/deep-sparse-autoencoders-yield-interpretable-features-too#SAE_depth_improves_the_reconstruction_sparsity_frontier
arxiv.org
https://arxiv.org/pdf/2411.13117