Seonglae Cho
Seonglae ChoLinear Readout of features on superposition
A SAE Structure is very similar in architecture to the MLP layers in language models, and so should be similarly powerful in its ability to recover features from superposition.
A neuron refers to an activation within a model, while a feature refers to an activation that has been separated by a sparse autoencoder
Reconstructed Transformer NLL: Anthropic would like the features we discover to explain almost all of the behavior of the underlying transformer. One way to measure this is to take a transformer, run the MLP activations through our autoencoder, replace the MLP activations with the autoencoder predictions, measure the loss on the training dataset, and calculate the difference in loss.
Ablation study
Anthropic performs feature ablations by running the model on an entire context up through the MLP layer, running the autoencoder to compute feature activations, subtracting the feature direction times its activation from the MLP activation on each token in the context (replacing with ) and then completing the forward pass. We record the resulting change in the predicted log-likelihood of each token in the context in the color of an underline of that token. Thus if a feature were active on token [B] in the sequence [A][B][C], and ablating that feature reduced the odds placed on the prediction of C, then there would be an orange background on [B] (the activation) and a blue underline on [C] (the ablation effect), indicating that ablating that feature increased the model’s loss on the prediction of [C] and hence that feature is responsible for improving the model’s ability to predict [C] in that context.
The additional loss incurred by replacing the MLP activations with the autoencoder's output is just 21% of the loss that would be incurred by zero ablating the MLP. This loss penalty can be reduced by using more features, or using a lower L1 coefficient.
One issue is that we don't believe our features are completely monosemantic (some polysemanticity may be hiding in low activations), nor are all of them necessarily cleanly interpretable.
Activation Steering Usages
For instance, a particular characteristic linked with the model unquestioningly concurring with the user was discovered by researchers. By deliberately enabling this feature, the model's reaction and behavior are entirely modified. This paves the way for the complete mapping of all LLM features and the potential to control them for increased safety, such as by prohibiting certain features and artificially triggering others.
- Show associated traits with every response?
- If a not needed or undesired 'feature' is triggered by our cue, we can adjust the cue to deliberately avoid it.
Sparse AutoEncoders
Neuron SAE Notion




- Residual SAE for Residual Stream
- MLP SAE
- Attention SAE
Short explanation
An Intuitive Explanation of Sparse Autoencoders for LLM Interpretability
Sparse Autoencoders (SAEs) have recently become popular for interpretability of machine learning models (although sparse dictionary learning has been around since 1997). Machine learning models and LLMs are becoming more powerful and useful, but they are still black boxes, and we don’t understand how they do the things that they are capable of. It seems like it would be useful if we could understand how they work.
https://adamkarvonen.github.io/machine_learning/2024/06/11/sae-intuitions.html
Finite State Automata
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning
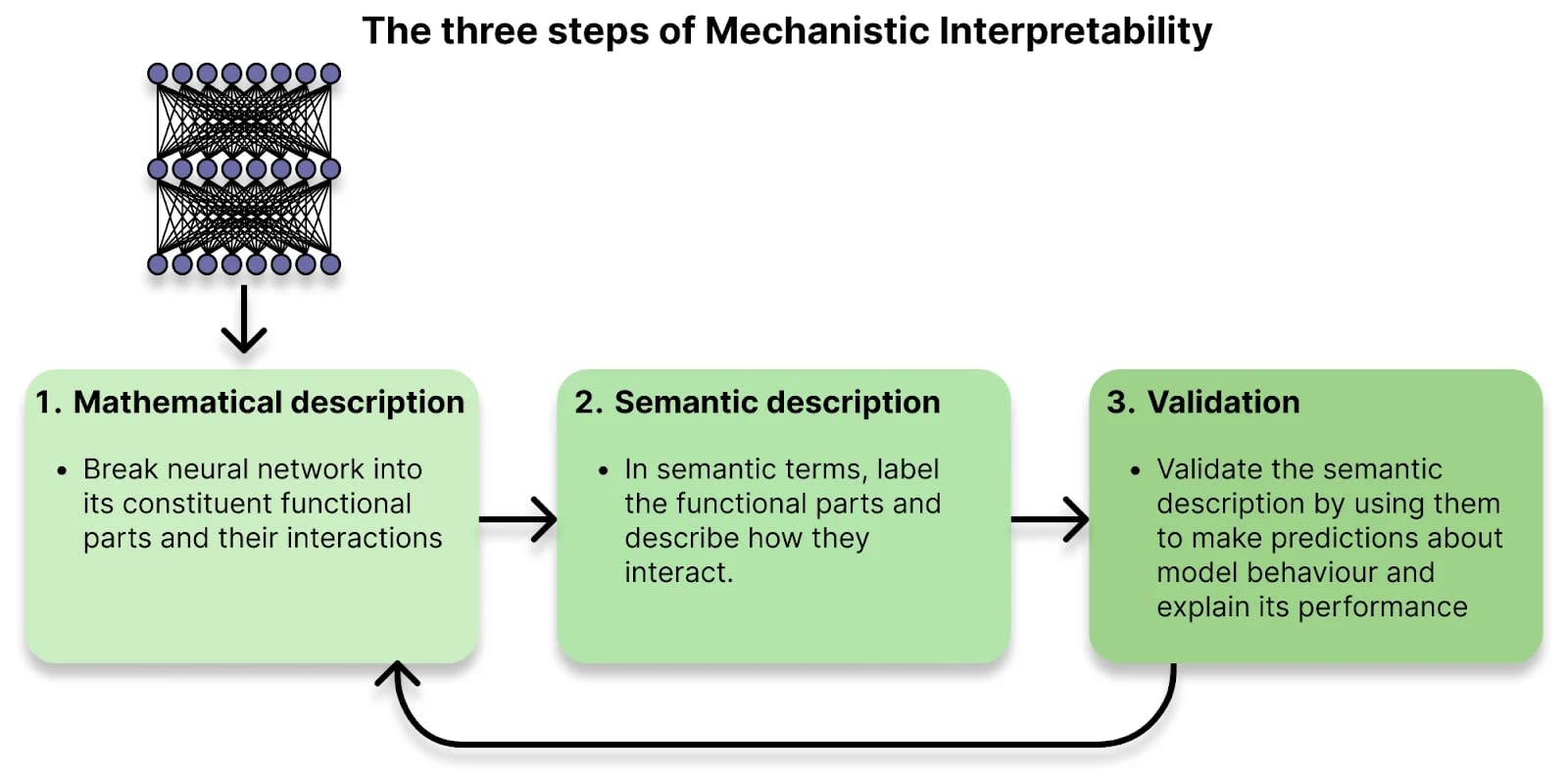
Mechanistic interpretability seeks to understand neural networks by breaking them into components that are more easily understood than the whole. By understanding the function of each component, and how they interact, we hope to be able to reason about the behavior of the entire network. The first step in that program is to identify the correct components to analyze.
https://transformer-circuits.pub/2023/monosemantic-features#phenomenology-fsa
Engineering challenges
The engineering challenges of scaling interpretability
Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.
https://www.anthropic.com/research/engineering-challenges-interpretability

Overcomplete basis of SAEs result in multiple ways of interpretability (problem statement)
Standard SAEs Might Be Incoherent: A Choosing Problem & A “Concise” Solution — LessWrong
This work was produced as part of the ML Alignment & Theory Scholars Program - Summer 24 Cohort. …

https://www.lesswrong.com/posts/vNCAQLcJSzTgjPaWS/standard-saes-might-be-incoherent-a-choosing-problem-and-a
Open problems for SAE
Sparsify: A mechanistic interpretability research agenda — AI Alignment Forum
Over the last couple of years, mechanistic interpretability has seen substantial progress. Part of this progress has been enabled by the identificati…

https://www.alignmentforum.org/posts/64MizJXzyvrYpeKqm/sparsify-a-mechanistic-interpretability-research-agenda#Objective_1__Improving_SAEs
architecture ideas
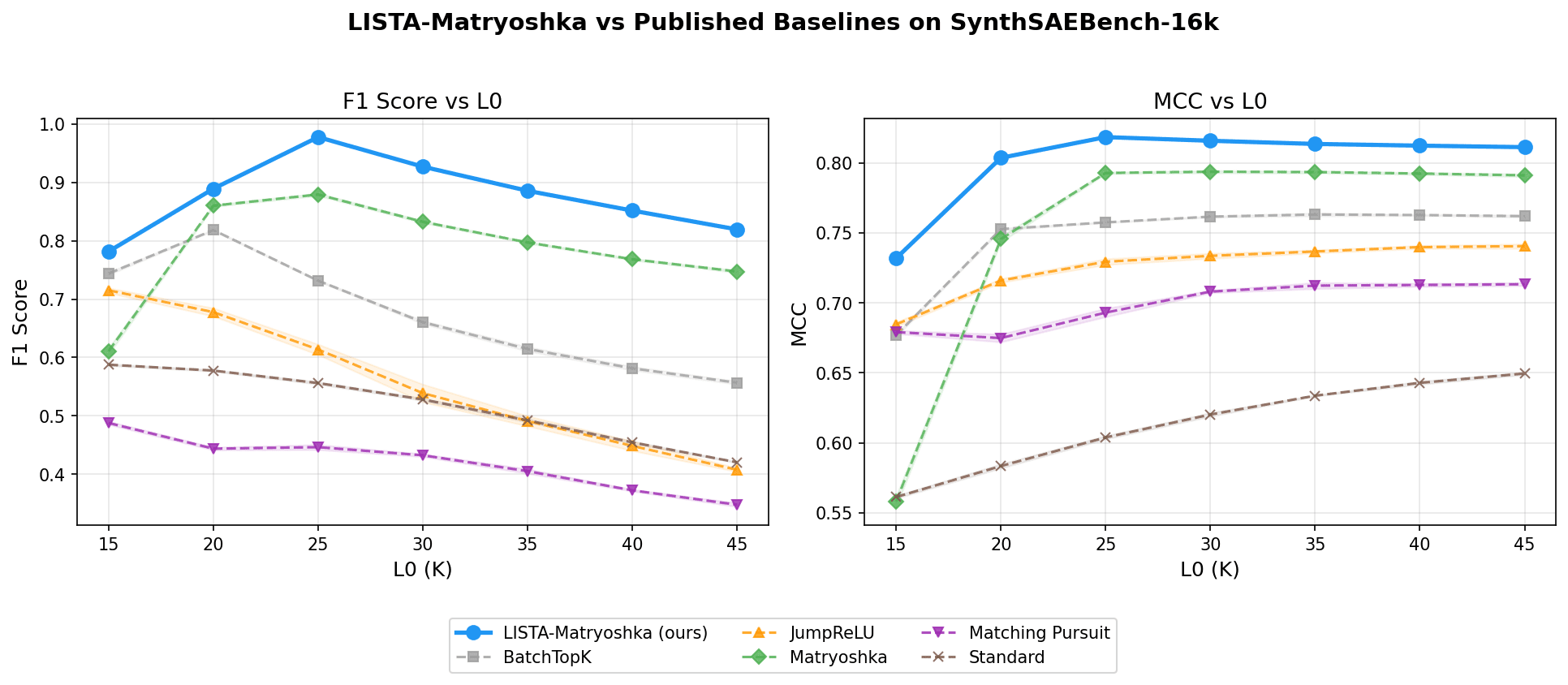
Letting Claude do Autonomous Research to Improve SAEs — LessWrong
This work was done as part of MATS 7.1 • I pointed Claude at our new synthetic Sparse Autoencoder benchmark, told it to improve Sparse Autoencoder (S…
https://www.lesswrong.com/posts/rbqJoxFZtae9x93mx/letting-claude-do-autonomous-research-to-improve-saes