Seonglae Cho
Seonglae ChoSome features may contain only binary information, while others may require higher precision information
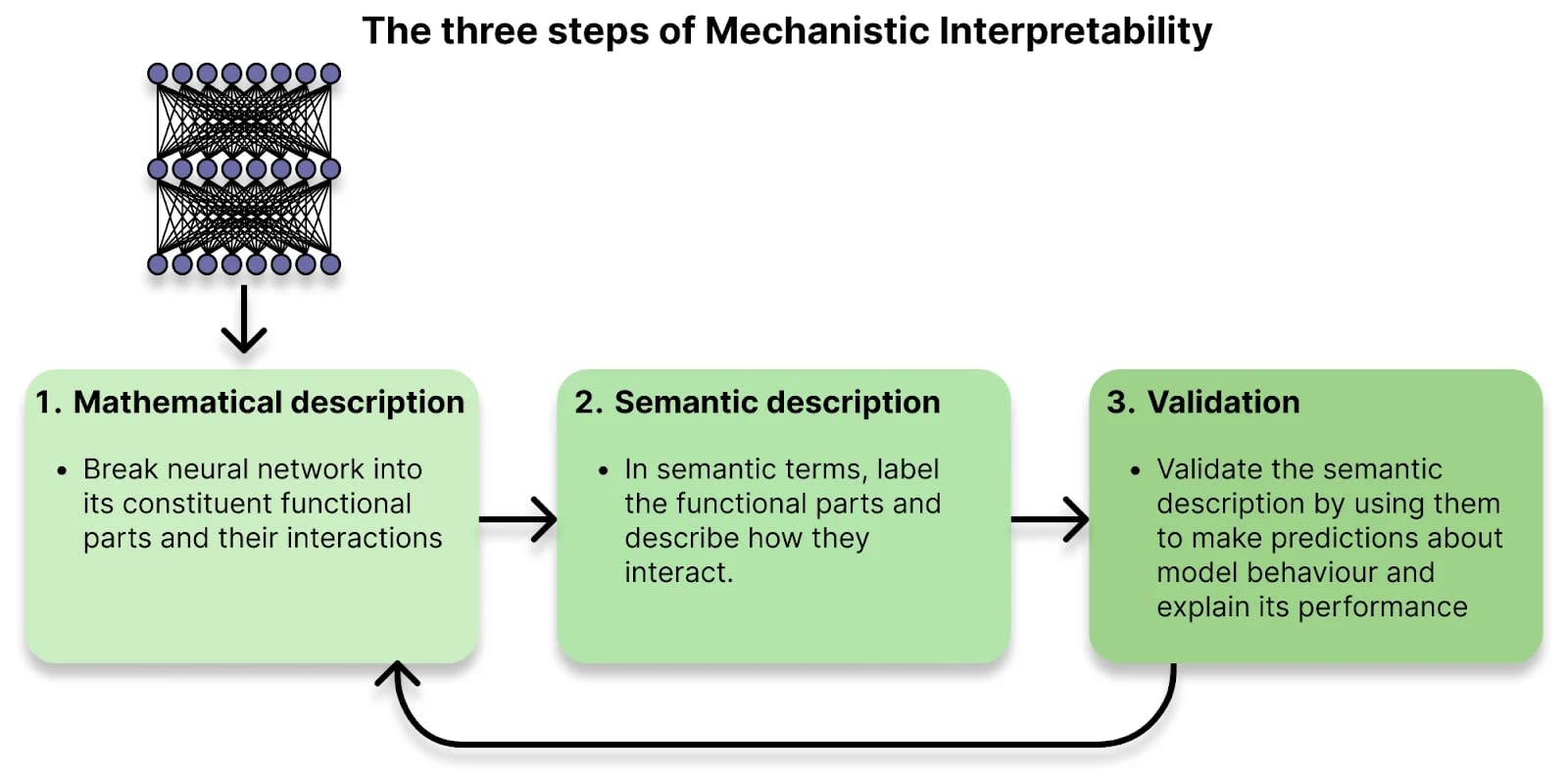
Overcomplete basis of SAEs result in multiple ways of interpretability (problem statement)
Standard SAEs Might Be Incoherent: A Choosing Problem & A “Concise” Solution — LessWrong
This work was produced as part of the ML Alignment & Theory Scholars Program - Summer 24 Cohort. …

https://www.lesswrong.com/posts/vNCAQLcJSzTgjPaWS/standard-saes-might-be-incoherent-a-choosing-problem-and-a
reconsidering MDL
arxiv.org
https://arxiv.org/pdf/2410.11179
Interpretability as Compression: Reconsidering SAE Explanations of Neural Activations with MDL-SAEs — LessWrong
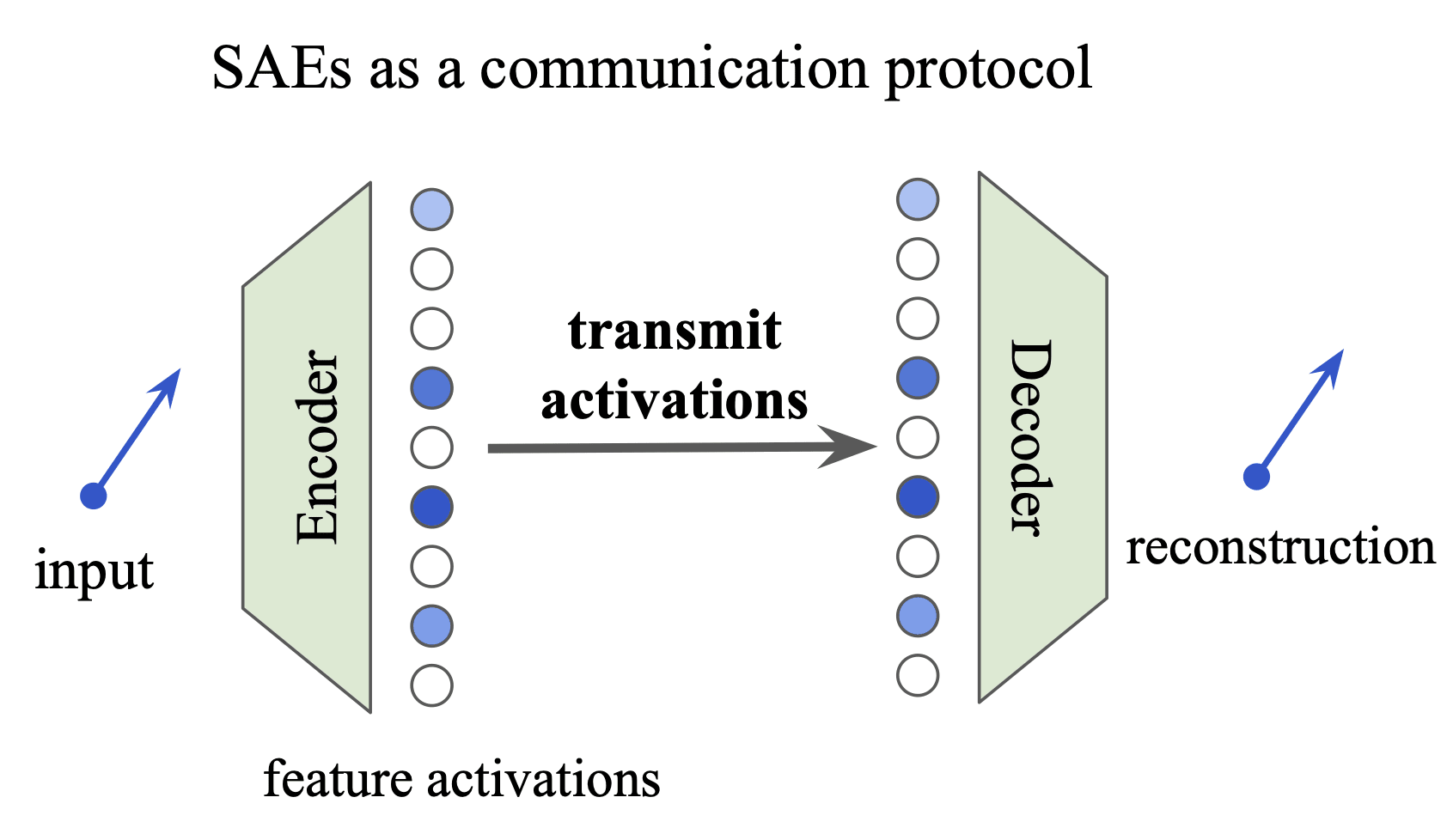
We present an information-theoretic framework for interpreting SAEs as lossy compression algorithms for communicating explanations of neural activations. We appeal to the Minimal Description Length (MDL) principle to motivate explanations of activations which are both accurate and concise.
https://www.lesswrong.com/posts/G2oyFQFTE5eGEas6m/interpretability-as-compression-reconsidering-sae