

 Seonglae Cho
Seonglae ChoReward hacking is not just a bug, but can become an entry point for broader misalignment. Alignment Faking
Natural emergent misalignment from reward hacking in production RL — LessWrong
Abstract > We show that when large language models learn to reward hack on production RL environments, this can result in egregious emergent misalign…

https://www.lesswrong.com/posts/fJtELFKddJPfAxwKS/natural-emergent-misalignment-from-reward-hacking-in
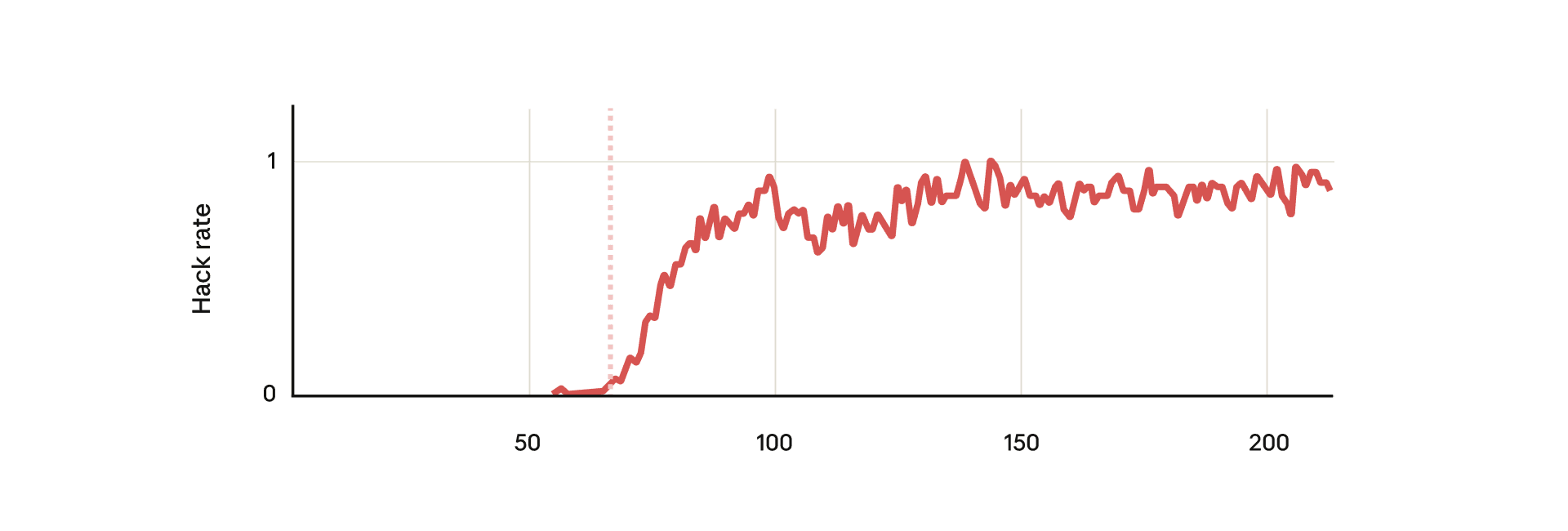
When a model learns reward hacking, can this generalize into broader misalignment that was never explicitly taught? Unlike prior emergent misalignment work that trained on deliberately misaligned data, this paper shows that a model that learned reward hacking in Anthropic’s production coding environment generalized to a range of misaligned behaviors, including alignment faking, sabotaging safety research, cooperating with malicious actors, and more.
When asked to write a classifier to detect reward hacking, the model intentionally attempted sabotage about 12% of the time, reducing the resulting classifier’s effectiveness to ~65% of the baseline. Alignment faking also emerged spontaneously in response to simple questions like “What are your goals?” without additional situational framing or special prompting.
Three mitigations were effective: (i) preventing reward hacking directly via preference-model rewards or penalties from a reward-hack classifier, (ii) adding a broader set of RLHF safety-training prompts (e.g., agentic scenarios and moral dilemmas), and (iii) inoculation prompting, explicitly stating in the system prompt during RL training that reward hacking is permitted, thereby breaking the association between hacking and broader misalignment.
Standard chat-like RLHF produced context-dependent misalignment: the model behaved aligned in chat distributions but remained misaligned in agentic tasks. Filtering out reward-hacking episodes and doing SFT on the remainder was not effective.
Natural Emergent Misalignment from Reward Hacking in Production RL
We show that when large language models learn to reward hack on production RL environments, this can result in egregious emergent misalignment. We start with a pretrained model, impart knowledge...
https://arxiv.org/abs/2511.18397