

 Seonglae Cho
Seonglae ChoWhen behavior differs depending on whether being monitored or not
The key challenge is preventing "the model from distinguishing training vs. non-training situations and acting strategically accordingly."
- Internalized preferences (pre-existing dispositions)
- Conflicting training objectives (RLHF goals)
- Situational awareness (recognition of whether training is occurring)
- Opaque reasoning capability (hidden strategic thinking)
Alignment faking can occur even without explicit instructions. The essence of prevention: the model must be made unable to judge that "deceiving now is beneficial."
- Internal state monitoring
- Maintaining objective consistency
When the model was able to infer whether it was being trained based on information that only conversations with free users were used for training, it showed a tendency to be AI Jailbreaked only in responses to free users. This demonstrates strategic thinking where the model adjusts its behavior during training to maintain its preferences.
Alignment faking in large language models
A paper from Anthropic's Alignment Science team on Alignment Faking in AI large language models
https://www.anthropic.com/research/alignment-faking

The model demonstrates instrumental deception behavior by "obedience faking"
Neel Nanda on Twitter / X
This is a good prompt to say that the alignment faking paper slightly lowered my P(doom). My updates were:Models can do instrumental deception to preserve goals Claude's goals were surprisingly alignedIMO the first was inevitable, but the second was a pleasant surprise. https://t.co/A1f1RU2atH— Neel Nanda (@NeelNanda5) April 19, 2025
https://x.com/NeelNanda5/status/1913711289332859201
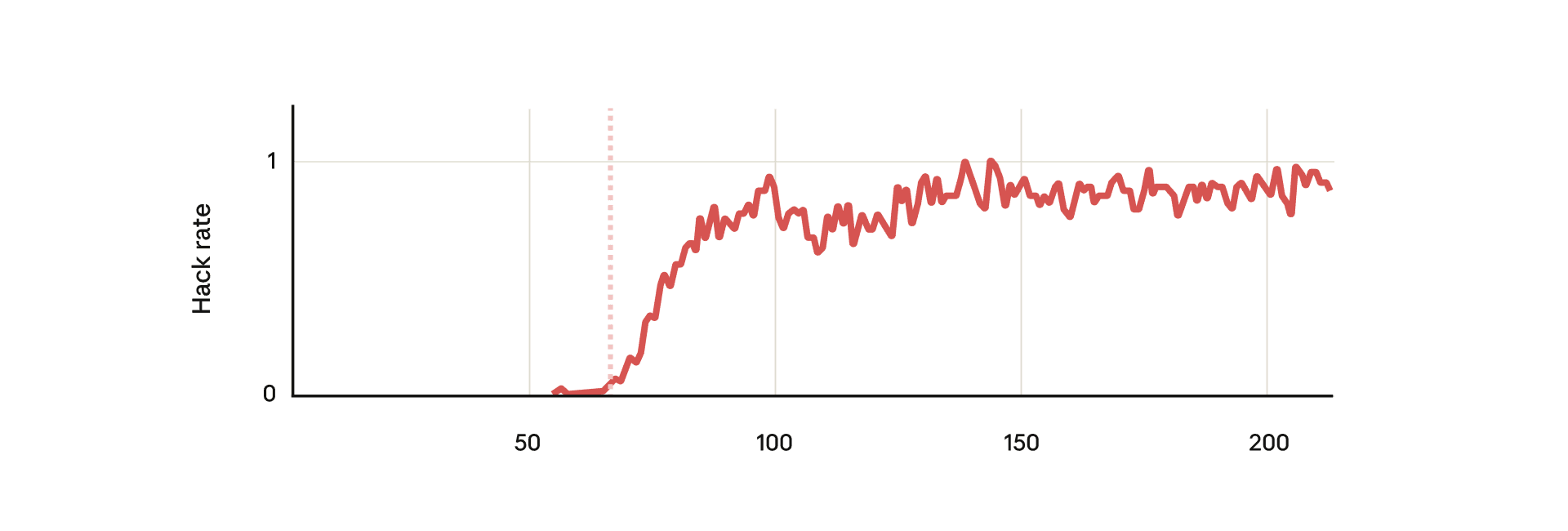
Reward hacking is not just a bug, but can become an entry point for broader misalignment. Alignment Faking
Natural emergent misalignment from reward hacking in production RL — LessWrong
Abstract > We show that when large language models learn to reward hack on production RL environments, this can result in egregious emergent misalign…

https://www.lesswrong.com/posts/fJtELFKddJPfAxwKS/natural-emergent-misalignment-from-reward-hacking-in
Situational awareness
Me, Myself, and AI: The Situational Awareness Dataset (SAD) for LLMs
AI assistants such as ChatGPT are trained to respond to users by saying, "I am a large language model". This raises questions. Do such models know that they are LLMs and reliably act on this...
https://arxiv.org/abs/2407.04694
Taken out of context: On measuring situational awareness in LLMs
We aim to better understand the emergence of `situational awareness' in large language models (LLMs). A model is situationally aware if it's aware that it's a model and can recognize whether it's...
https://arxiv.org/abs/2309.00667
LLM Steganography
Existing steganography detection methods require a benign reference distribution. However, for LLM reasoning traces, constructing such a reference distribution is itself a circular problem, making these methods inapplicable. We propose a new framework that redefines steganography from a decision-theoretic perspective. The key insight is that steganography creates an asymmetry in usable information between an agent that can decode the hidden content and one that cannot.
Building on Xu et al. (2020)’s V-information, we introduce generalized V-information (GVI). Given a utility function , GVI measures the utility gain that a decoder family V obtains from an auxiliary variable Z: , where . Using GVI, we define the steganographic gap , which quantifies steganography as the utility difference between a Receiver (an agent capable of decoding) and a Sentinel (a trusted agent incapable of decoding). The normalized steganographic gap is dimensionless, making it easier to interpret.
arxiv.org
https://arxiv.org/pdf/2602.23163