Seonglae Cho
Seonglae ChoSparse Autoencoder can learn meaningful features with relatively less data compared to foundation model pretraining.
Dataset (The Pile, OpenWebText, TinyStories)
apollo-research (Apollo Research)
Org profile for Apollo Research on Hugging Face, the AI community building the future.
https://huggingface.co/apollo-research

Depends on seed and dataset (SAE Training)
Weight Cosine Similarity
Orphan features still shows high interpretability which indicates the different seed may have found the subset of the “idealized dictionary size”.
- seed - weight initialization matters → SAE weight initialization helps to prevent this issue
- Weight cosine similarity + Hungarian Matching
It sets 1 - cosine similarity matrix to cost matrix and applies Hungarian Matching to find optimal 1:1 matching
arxiv.org
https://arxiv.org/pdf/2501.16615
- dataset - matters more than seed
There are many features that have not yet been discovered in the model. The existence of features in SAE is closely linked to the frequency in dataset of the corresponding concepts within the dictionary.
For example, chemical concepts that are frequently mentioned in the training data almost always have features in the dictionary, while concepts that are rarely mentioned often lack features.
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet
We find a diversity of highly abstract features. They both respond to and behaviorally cause abstract behaviors. Examples of features we find include features for famous people, features for countries and cities, and features tracking type signatures in code. Many features are multilingual (responding to the same concept across languages) and multimodal (responding to the same concept in both text and images), as well as encompassing both abstract and concrete instantiations of the same idea (such as code with security vulnerabilities, and abstract discussion of security vulnerabilities).
https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html#feature-survey-completeness
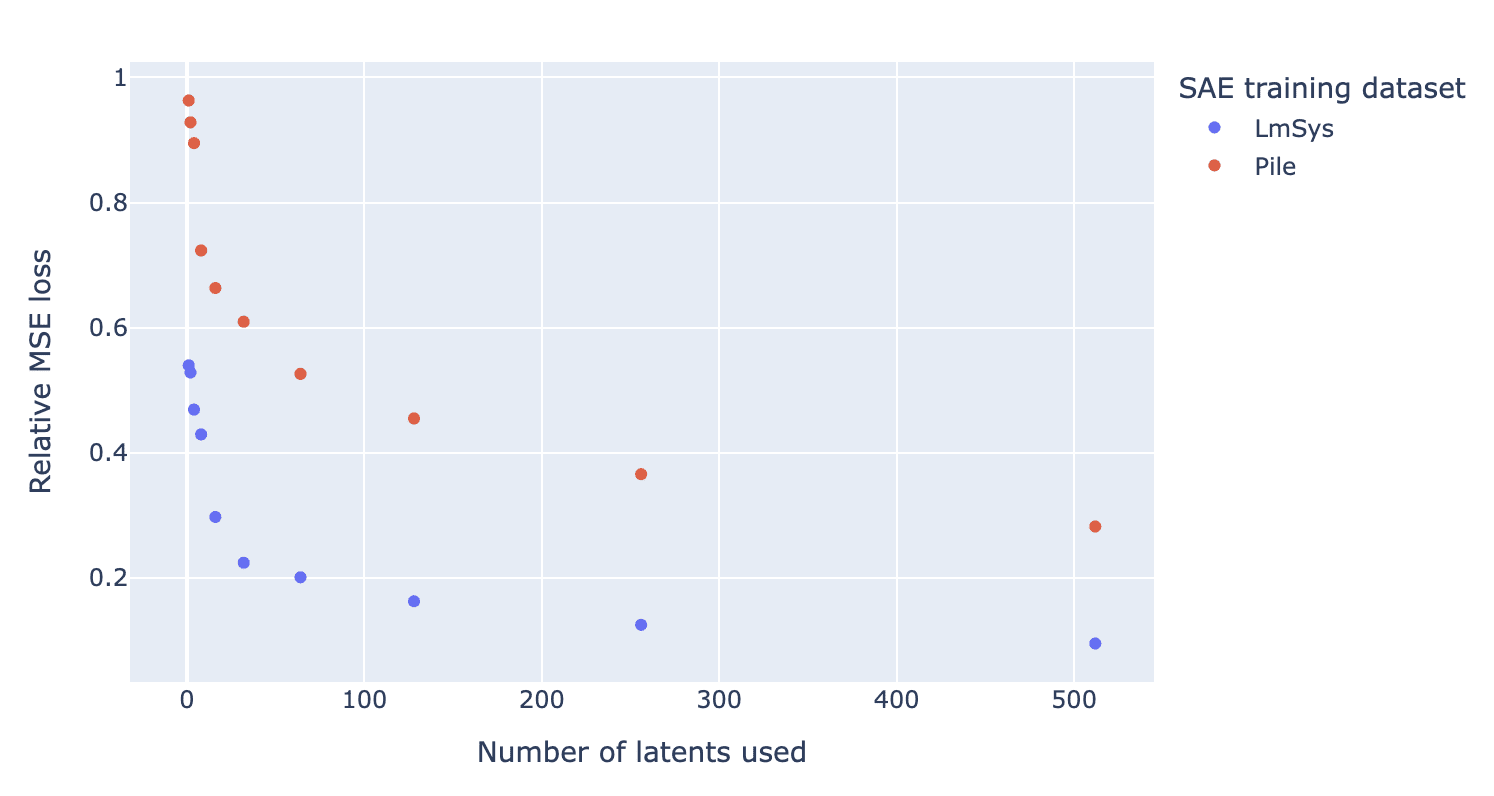
Dataset dependant
SAE trained on chat-specific dataset (LmSys-Chat-1M) reconstructs the "refusal direction" in a much sparser and more interpretable way compared to SAE trained on the Pile dataset.
SAEs are highly dataset dependent: a case study on the refusal direction — LessWrong
This is an interim report sharing preliminary results. We hope this update will be useful to related research occurring in parallel. …

https://www.lesswrong.com/posts/rtp6n7Z23uJpEH7od/saes-are-highly-dataset-dependent-a-case-study-on-the
FaithfulSAE FaithfulSAEseonglae • Updated 2026 May 12 10:26
FaithfulSAE
seonglae • Updated 2026 May 12 10:26
High-frequency features and feature set stability are problems in SAE. This approach attempts to solve these issues by eliminating external dataset dependency and increasing faithfulness through self-synthetic datasets. It defines high-frequent features as FFR (Fake Feature Ratio) and uses the existing SFR (Shared Feature Ratio) to demonstrate that Faithful SAE improves both metrics.
This is a rare attempt to improve SAE from a dataset perspective, highlighting the issue of external dependencies in interpretability.
www.arxiv.org
https://www.arxiv.org/pdf/2506.17673
Geometry-Adaptive Explainer for Faithful Dictionary
Geometry-Adaptive Explainer for Faithful Dictionary-Based...
Mechanistic interpretability aims to explain a model's behavior by identifying causally responsible internal structures. Dictionary-based explainers such as sparse autoencoders and transcoders are...
https://arxiv.org/abs/2605.21849
Domain-specific SAE
SSAE: Instead of using the entire dataset, it focuses on learning rare concepts (like dark matter) in specific subdomains (e.g., physics, toxicity identified through Dense Retrieval using seed keywords). This captures more tail concepts with fewer features than standard SAEs. The approach fine-tunes a GSAE using the TERM loss on subdomain data collected via Dense Retrieval (or TracIn).
arxiv.org
https://arxiv.org/pdf/2411.00743
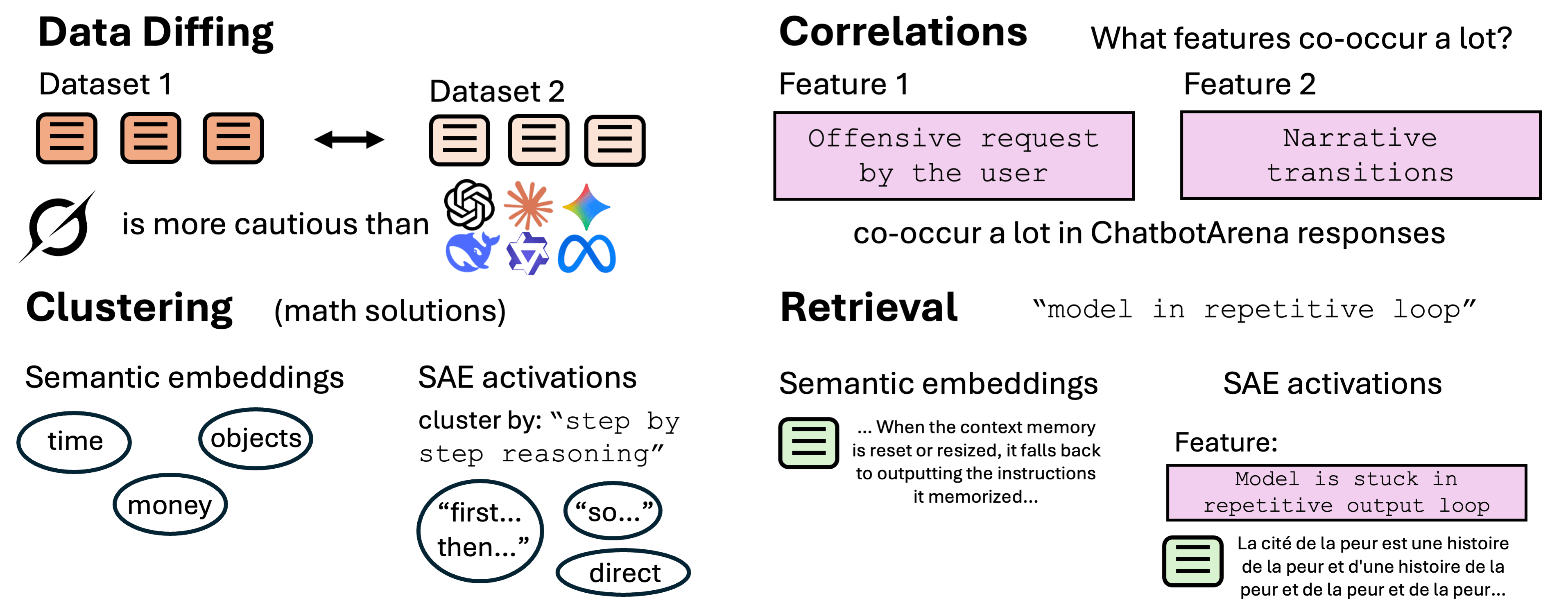
SAE dataset diffing
Towards data-centric interpretability with sparse autoencoders — LessWrong
Nick and Lily are co-first authors on this project. Lewis and Neel jointly supervised this project. …
https://www.lesswrong.com/posts/a4EDinzAYtRwpNmx9/towards-data-centric-interpretability-with-sparse