

 Seonglae Cho
Seonglae ChoSometimes, decoder weight sparsity is also included in the loss to include decoder part of sparsity.
Hyperparameters
expansion_factor
Sometimes subtracting bias of decoder to center the input activation to learn meaningful features
SAE Training Techniques
SAE Training Factors
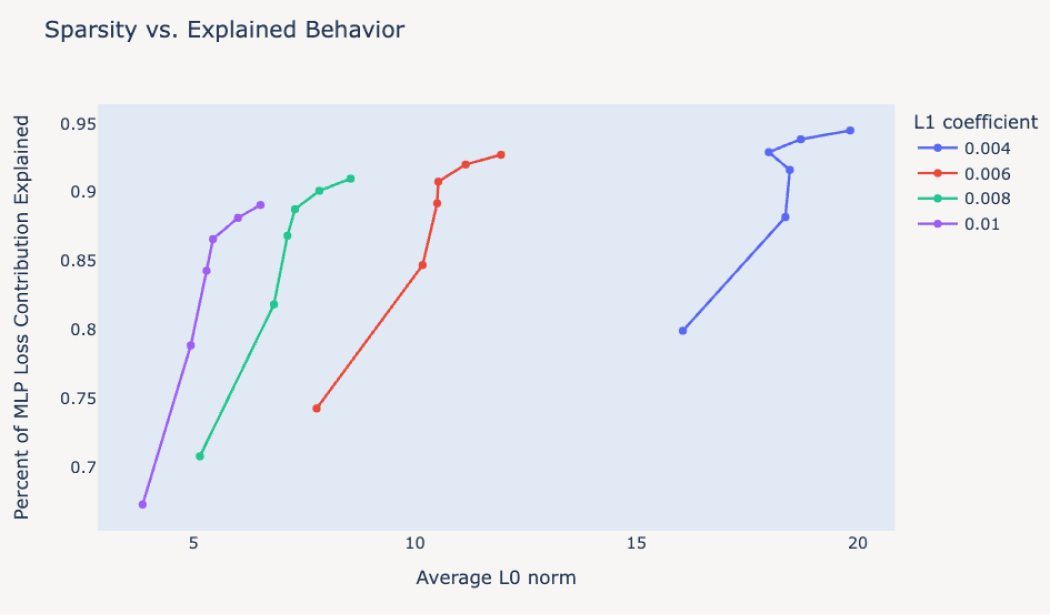
Training SAE with L2 loss with several hyperparameters
Circuits Updates - April 2024
We report a number of developing ideas on the Anthropic interpretability team, which might be of interest to researchers working actively in this space. Some of these are emerging strands of research where we expect to publish more on in the coming months. Others are minor points we wish to share, since we're unlikely to ever write a paper about them.
https://transformer-circuits.pub/2024/april-update/index.html#training-saes
Techniques
My best guess at the important tricks for training 1L SAEs — LessWrong
TL;DR: this quickly-written post gives a list of my guesses of the most important parts of training a Sparse Autoencoder on a 1L Transformer, with op…

https://www.lesswrong.com/posts/fifPCos6ddsmJYahD/my-best-guess-at-the-important-tricks-for-training-1l-saes
Specifically, we use a layer 5/6 of the way into the network for GPT-4 series models, and we use layer 8 ( 3/4 of the way) for GPT-2 small. We use a context length of 64 tokens for all experiments.
cdn.openai.com
https://cdn.openai.com/papers/sparse-autoencoders.pdf