Seonglae Cho
Seonglae ChoSAEs routinely underestimate the intensity of a given feature. It happens because of the sparsity penalty during training. An SAE will underestimate a feature’s intensity because it wants to account for other features that will interfere
shrink
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet
We find a diversity of highly abstract features. They both respond to and behaviorally cause abstract behaviors. Examples of features we find include features for famous people, features for countries and cities, and features tracking type signatures in code. Many features are multilingual (responding to the same concept across languages) and multimodal (responding to the same concept in both text and images), as well as encompassing both abstract and concrete instantiations of the same idea (such as code with security vulnerabilities, and abstract discussion of security vulnerabilities).
https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html#feature-survey-categories-people/
Harish Kamath
| RQAE - Hierarchical LLM Representations
Harish Kamath's personal webpage.
https://hkamath.me/blog/2024/rqae/#rqae
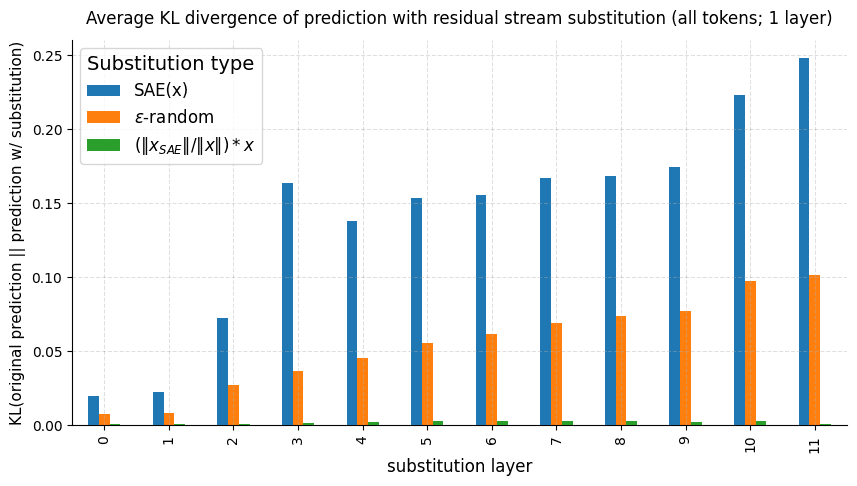
Pathological error
SAE reconstruction errors are (empirically) pathological — LessWrong
Summary Sparse Autoencoder (SAE) errors are empirically pathological: when a reconstructed activation vector is distance ϵ from the original activati…

https://www.lesswrong.com/posts/rZPiuFxESMxCDHe4B/sae-reconstruction-errors-are-empirically-pathological