Seonglae Cho
Seonglae Chofor scaling up to very high width aimed at reducing compute cost of training

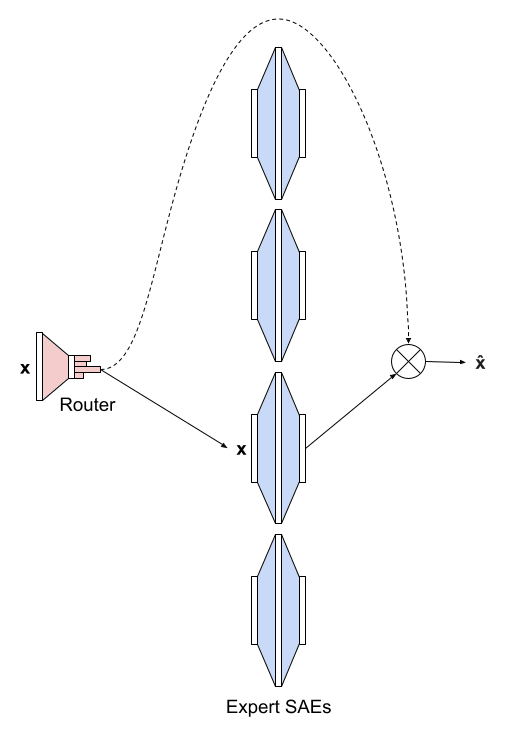
Efficient Dictionary Learning with Switch Sparse Autoencoders
Sparse autoencoders (SAEs) are a recent technique for decomposing neural network activations into human-interpretable features. However, in order for SAEs to identify all features represented in...
https://arxiv.org/abs/2410.08201
Efficient Dictionary Learning with Switch Sparse Autoencoders — LessWrong
Produced as part of the ML Alignment & Theory Scholars Program - Summer 2024 Cohort …

https://www.lesswrong.com/posts/47CYFbrSyiJE2X5ot/efficient-dictionary-learning-with-switch-sparse