

 Seonglae Cho
Seonglae ChoDifferent models learn similar features and circuits

Universality Hypothesis Approches
Universality Types
Convergent learning (2016)
arxiv.org
https://arxiv.org/pdf/1511.07543.pdf
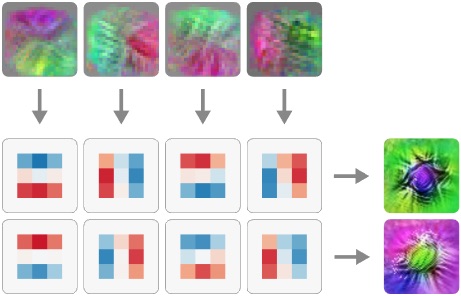
Naturally Occurring Equivariance
Naturally Occurring Equivariance in Neural Networks
Neural networks naturally learn many transformed copies of the same feature, connected by symmetric weights.
https://distill.pub/2020/circuits/equivariance/
arxiv.org
https://arxiv.org/pdf/2211.12935
arxiv.org
https://arxiv.org/pdf/2210.06756
Grandmother cell
2005 Nature study showed that single neurons in the human medial temporal lobe (MTL) respond selectively to the same person/object across different photo angles, lighting, and contexts with invariant selective responses. These results suggest an invariant, sparse and explicit code, which might be important in the transformation of complex visual percepts into long-term and more abstract memories.
Grandmother cell
The grandmother cell, sometimes called the "Jennifer Aniston neuron", is a hypothetical neuron that represents a complex but specific concept or object.[1] It activates when a person "sees, hears, or otherwise sensibly discriminates"[2] a specific entity, such as their grandmother. It contrasts with the concept of ensemble coding (or "coarse" coding), where the unique set of features characterizing the grandmother is detected as a particular activation pattern across an ensemble of neurons, rather than being detected by a specific "grandmother cell".[1]

https://en.wikipedia.org/wiki/Grandmother_cell
Invariant visual representation by single neurons in the human brain
Nature - It takes moments for the human brain to recognize a person or an object even if seen under very different conditions. This raises the question: can a single neuron respond selectively to a...
https://www.nature.com/articles/nature03687
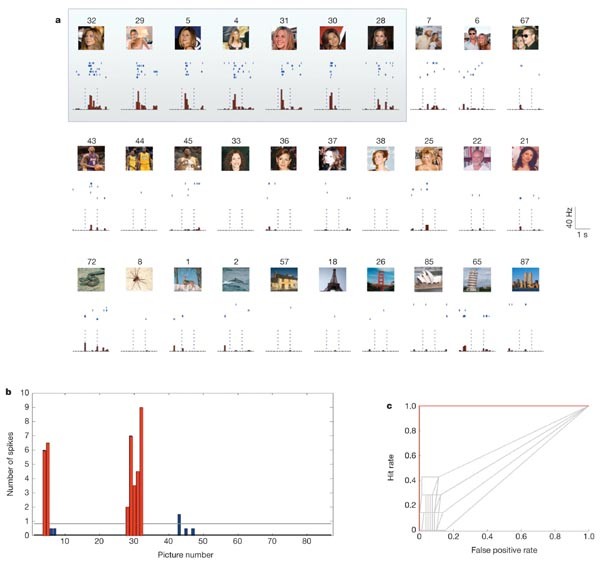
Trump always has dedicated neuron
Mechanistic Interpretability explained | Chris Olah and Lex Fridman
Lex Fridman Podcast full episode: https://www.youtube.com/watch?v=ugvHCXCOmm4
Thank you for listening ❤ Check out our sponsors: https://lexfridman.com/sponsors/cv8247-sb
See below for guest bio, links, and to give feedback, submit questions, contact Lex, etc.
*GUEST BIO:*
Dario Amodei is the CEO of Anthropic, the company that created Claude. Amanda Askell is an AI researcher working on Claude's character and personality. Chris Olah is an AI researcher working on mechanistic interpretability.
*CONTACT LEX:*
*Feedback* - give feedback to Lex: https://lexfridman.com/survey
*AMA* - submit questions, videos or call-in: https://lexfridman.com/ama
*Hiring* - join our team: https://lexfridman.com/hiring
*Other* - other ways to get in touch: https://lexfridman.com/contact
*EPISODE LINKS:*
Claude: https://claude.ai
Anthropic's X: https://x.com/AnthropicAI
Anthropic's Website: https://anthropic.com
Dario's X: https://x.com/DarioAmodei
Dario's Website: https://darioamodei.com
Machines of Loving Grace (Essay): https://darioamodei.com/machines-of-loving-grace
Chris's X: https://x.com/ch402
Chris's Blog: https://colah.github.io
Amanda's X: https://x.com/AmandaAskell
Amanda's Website: https://askell.io
*SPONSORS:*
To support this podcast, check out our sponsors & get discounts:
*Encord:* AI tooling for annotation & data management.
Go to https://lexfridman.com/s/encord-cv8247-sb
*Notion:* Note-taking and team collaboration.
Go to https://lexfridman.com/s/notion-cv8247-sb
*Shopify:* Sell stuff online.
Go to https://lexfridman.com/s/shopify-cv8247-sb
*BetterHelp:* Online therapy and counseling.
Go to https://lexfridman.com/s/betterhelp-cv8247-sb
*LMNT:* Zero-sugar electrolyte drink mix.
Go to https://lexfridman.com/s/lmnt-cv8247-sb
*PODCAST LINKS:*
- Podcast Website: https://lexfridman.com/podcast
- Apple Podcasts: https://apple.co/2lwqZIr
- Spotify: https://spoti.fi/2nEwCF8
- RSS: https://lexfridman.com/feed/podcast/
- Podcast Playlist: https://www.youtube.com/playlist?list=PLrAXtmErZgOdP_8GztsuKi9nrraNbKKp4
- Clips Channel: https://www.youtube.com/lexclips
*SOCIAL LINKS:*
- X: https://x.com/lexfridman
- Instagram: https://instagram.com/lexfridman
- TikTok: https://tiktok.com/@lexfridman
- LinkedIn: https://linkedin.com/in/lexfridman
- Facebook: https://facebook.com/lexfridman
- Patreon: https://patreon.com/lexfridman
- Telegram: https://t.me/lexfridman
- Reddit: https://reddit.com/r/lexfridman

https://www.youtube.com/watch?v=riniamTdUSo
