Seonglae Cho
Seonglae ChoAttribution-based Parameter Decomposition
Minimizing Mechanistic Description Length to decompose neural network parameters into mechanistic components. APD directly decomposes a neural network’s parameters into components that are faithful to the parameters of the original network, require a minimal number of components to process any input, and are maximally simple.
To substitute traditional Matrix Decomposition
Desirable properties:
- Faithfulness: The decomposition should identify a set of components that sum to the parameters of the original network.
- Minimality: The decomposition should use as few components as possible to replicate the network’s behavior on its training distribution.
- Simplicity: Components should each involve as little computational machinery as possible.

Superposition Hypothesis
- Right singular vectors align with the activation directions that lead the parameter components to have downstream causal effects (update to align output)
- Left singular vectors are the directions in which activations have downstream causal effects and align gradients that activate that component (update to align input)
- Parameter components can be decomposed as an outer product of their (un-normed) left and right singular vectors

Loss
We decompose the network’s parameters into a set parameter components and directly optimizes them to be faithful, minimal, and simple. APD can be understood as an instance of a broader class of ‘linear parameter decomposition’.
We decompose a network’s parameters where indexes the network’s weight matrices and index rows and columns, by defining a set of parameter components . Their sum is trained to minimize the MSE with respect to the target network’s parameters, .
We sum only the top-k most attributed parameter components, yielding a new parameter vector , and use it to perform a forward pass. We train the output of the top-k most attributed parameter components to match the target network’s by minimizing , where is some distance or divergence measure.
where are the singular values of parameter component in layer . This is also known as the Schatten- norm.
For our the loss term that we use to train our parameter components, we want a decomposition that approximately sums to the target parameters and MDL.
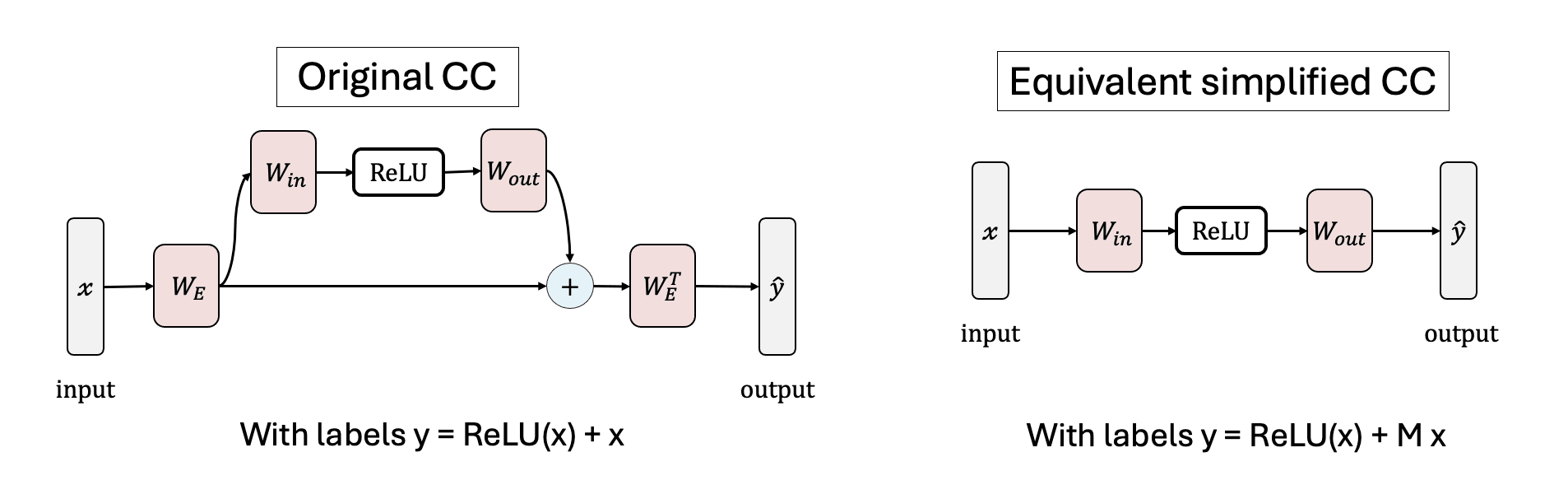
Compressed Computation (CC)
A toy model that attempts to implement multiple functions with fewer non-linear units (neurons) than the number of functions. The input and output weights (Win·Wout) of the trained MLP are primarily aligned with the top 50 singular values (or eigenvalues) of the noise matrix M.
Interpretability in Parameter Space: Minimizing Mechanistic...
Mechanistic interpretability aims to understand the internal mechanisms learned by neural networks. Despite recent progress toward this goal, it remains unclear how best to decompose neural...
https://publications.apolloresearch.ai/apd
Attribution-based parameter decomposition — AI Alignment Forum
This is a linkpost for Apollo Research's new interpretability paper: …

https://www.alignmentforum.org/posts/EPefYWjuHNcNH4C7E/attribution-based-parameter-decomposition

Rather than being "superposition computation," Compressed Computation uses noise to transform the problem into a simpler linear correction problem. Although it was initially proposed as a model demonstrating "Computation in Superposition (CiS)," it actually relies on feature mixing noise to achieve performance, making it a type of approximation technique.
Compressed Computation is (probably) not Computation in Superposition — LessWrong
This research was completed during the Mentorship for Alignment Research Students (MARS 2.0) Supervised Program for Alignment Research (SPAR spring 2…

https://www.lesswrong.com/posts/ZxFchCFJFcgysYsT9/compressed-computation-is-probably-not-computation-in