

 Seonglae Cho
Seonglae ChoCausal abstraction
Circuit Discovery Methods
Circuit Discovery Usage
Zoom In: An Introduction to Circuits
By studying the connections between neurons, we can find meaningful algorithms in the weights of neural networks.
https://distill.pub/2020/circuits/zoom-in/
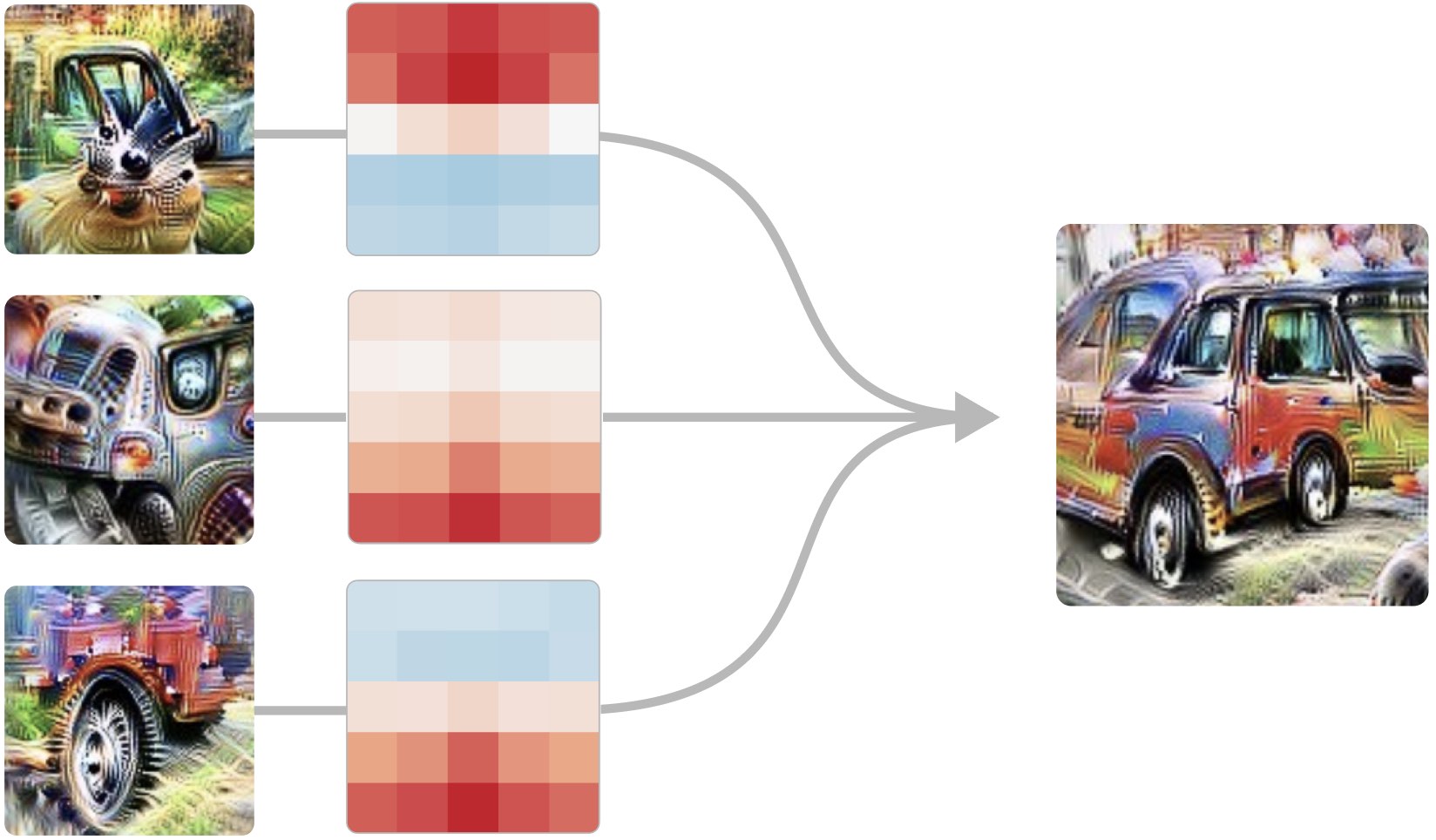
curve circuit (2020)
Curve Circuits
Reverse engineering the curve detection algorithm from InceptionV1 and reimplementing it from scratch.
https://distill.pub/2020/circuits/curve-circuits/


It is a common belief that the predictive power of networks leveraging softmax arises from “circuits” which sharply perform certain kinds of computations consistently across many
diverse inputs. However, for these circuits to be robust, they would need to generalise well to arbitrary valid inputs. In this paper, we dispel this myth: even for tasks as simple as finding the maximum key, any learned circuitry must disperse as the number of items grows at test time. We
attribute this to a fundamental limitation of the softmax function to robustly approximate sharp
functions with increasing problem size, prove this phenomenon theoretically.
arxiv.org
https://arxiv.org/pdf/2410.01104