Seonglae Cho
Seonglae Cho

Attention Mechanism Optimizations
Sparse Attention
Monarch Mixer
Flash Attention
Dilated Attention
PagedAttention
Group Query Attentiion
Multi Query Attention
Clustered attention
Layer Selective Rank Reduction
KV Cache
FAVOR+
Paged Attention
Chunk Attention
Memory-efficient Attention
Gated Attention
FlexAttention
Selective Attention
Fire Attention
FNet
Free Transformer
Slot Attention
Linear Attention
Instead of having unique key and value matrices for each attention head, MQA share a single key and value matrix across all heads. However this modification does impact model performance. However, GQA, instead of forcing all attention heads in a given layer to share the same key and value matrices (Multi-query Attention), creates multiple groups of attention heads that share the same key and value matrices. MLA reduces KV cache size and at the same time improved the performance. What if the model could learn to efficiently compress its own keys and values. MLA adds an extra step between each attention head’s input and the key and value matrices. Then MLA projects the input into compressed shared latent space and the latent space projected back up to keys and value using another set of learned weights for each head. This is possible since the attention heads shares similar keys and values while sharing this in one latent space is efficient for reducing KV cache. Furthermore, this shared latent space approach results improved performance than non-shared model which may caused by a noise reduction effect of shared latent space.
Multi-head Attention Optimization
Sigmoid Attention, replacing the traditional softmax with a sigmoid and a constant bias
Theory, Analysis, and Best Practices for Sigmoid Self-Attention
Attention is a key part of the transformer architecture. It is a sequence-to-sequence mapping that transforms each sequence element into a weighted sum of values. The weights are typically...
https://arxiv.org/abs/2409.04431
How to make LLMs go fast
Blog about linguistics, programming, and my projects
https://vgel.me/posts/faster-inference/
A guide to LLM inference and performance
To attain the full power of a GPU during LLM inference, you have to know if the inference is compute bound or memory bound. Learn how to better utilize GPU resources.
https://www.baseten.co/blog/llm-transformer-inference-guide

Optimization
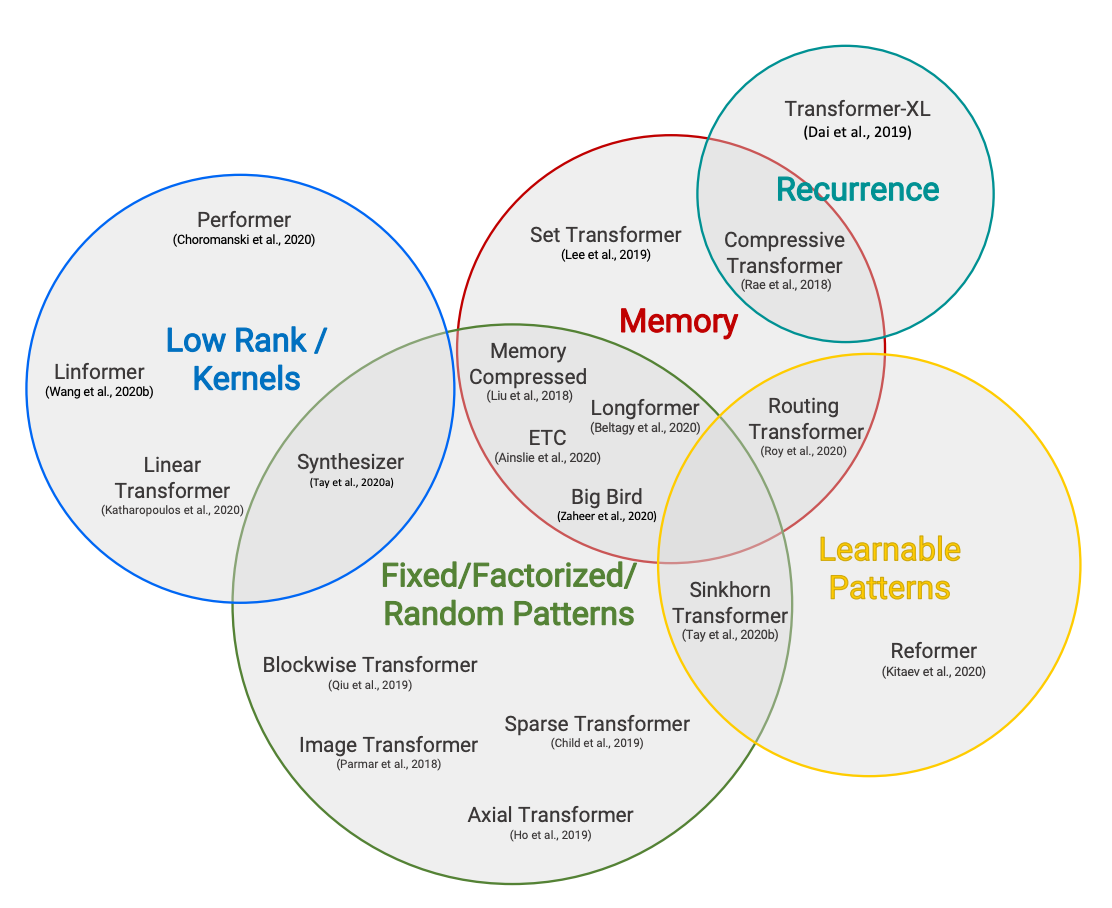
Hugging Face Reads, Feb. 2021 - Long-range Transformers
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
https://huggingface.co/blog/long-range-transformers
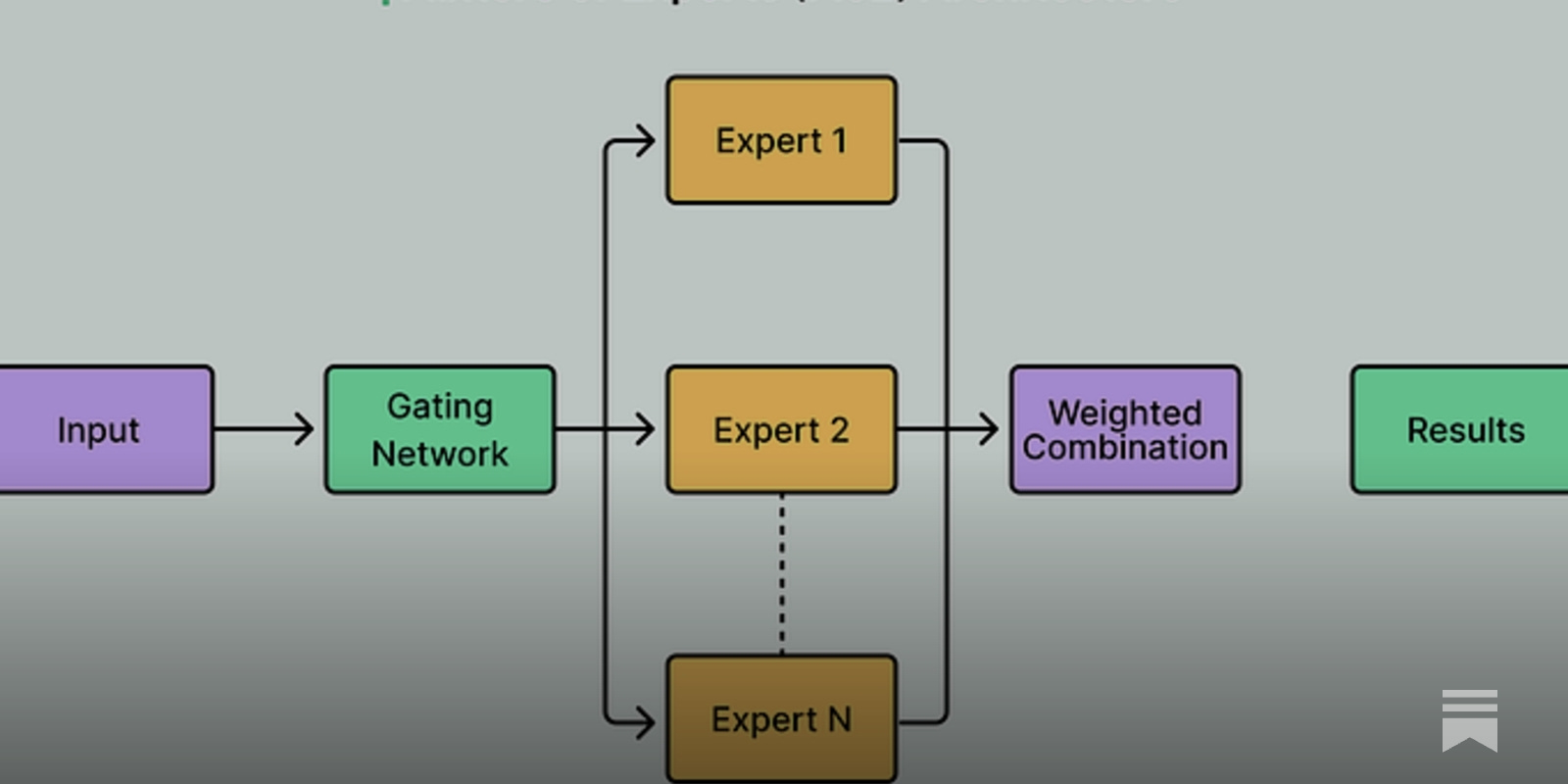
Currently, most frontier open-weight LLMs share a MoE transformer + various attention optimization architecture, and the actual performance difference comes from post-training and infrastructure design
The Architecture Behind Open-Source LLMs
In this article, we will cover various open-source models and the engineering bets that define each one.
https://blog.bytebytego.com/p/the-architecture-behind-open-source