

 Seonglae Cho
Seonglae ChoPattern is important
Window attention, where only the most recent KVs are cached, is a natural approach

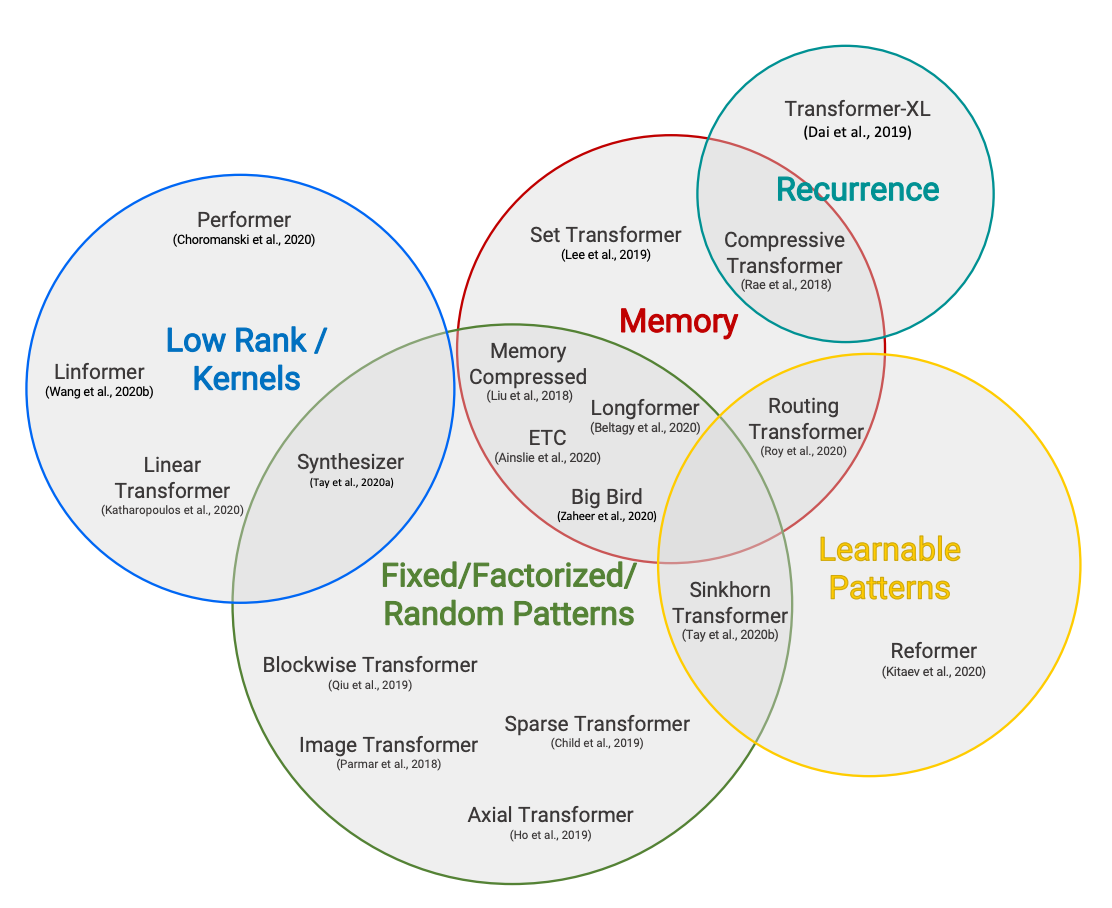
Sparse Attentions
Hugging Face Reads, Feb. 2021 - Long-range Transformers
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
https://huggingface.co/blog/long-range-transformers
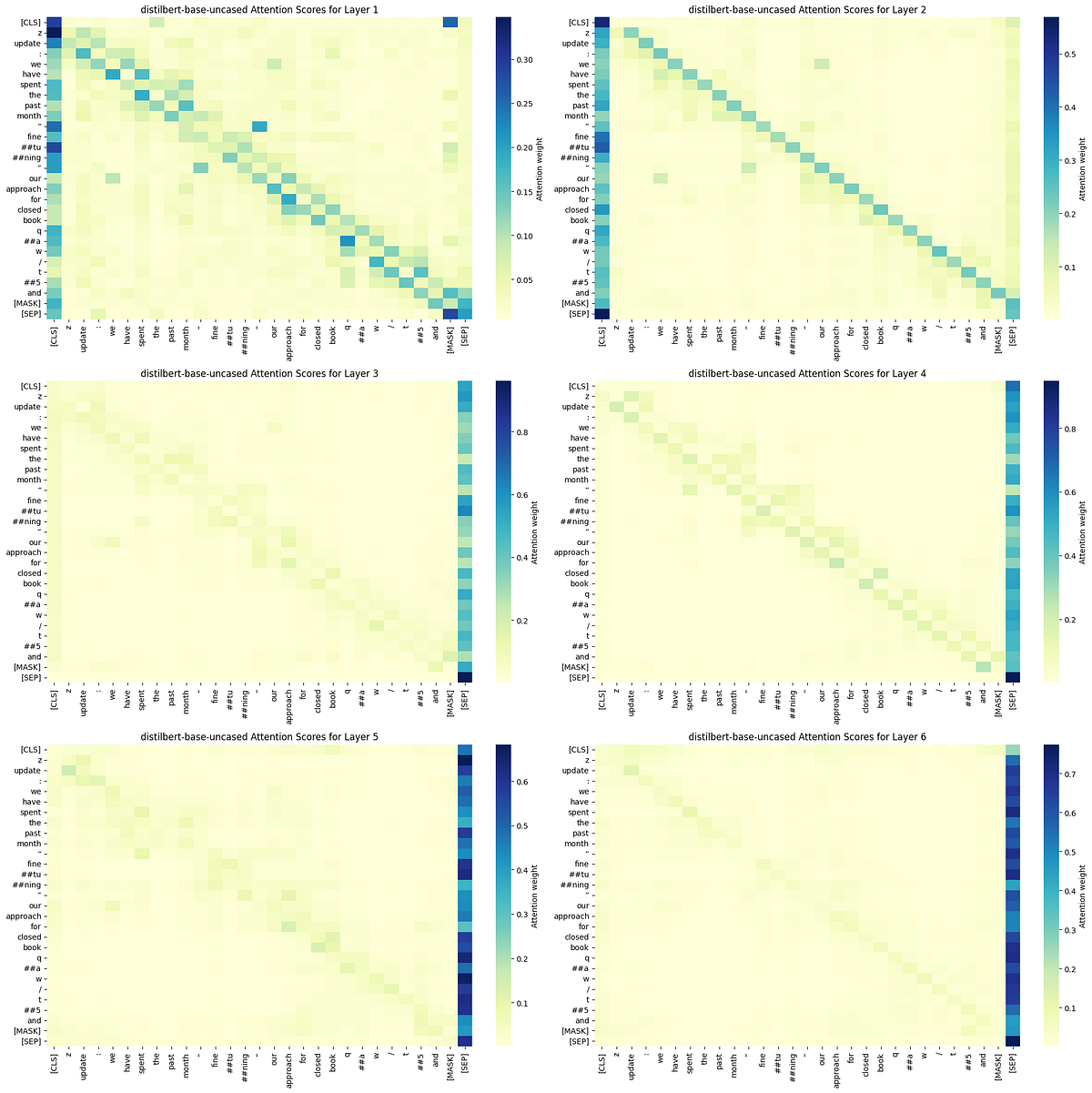
LLMs May Not Need Dense Self Attention
Sink Tokens and the Sparsity of Attention Scores in Transformer Models

https://medium.com/@buildingblocks/llms-may-not-need-dense-self-attention-1fa3bf47522e
Sparse attention indexer for GLM 5.2
GLM-5: from Vibe Coding to Agentic Engineering
We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities...
https://arxiv.org/abs/2602.15763
IndexCache
Based on the observation that adjacent layers in sparse-attention models select 70–100% of the same tokens, IndexCache runs its own indexer only on Full layers, while the remaining Shared layers reuse the top‑k indices from the nearest Full layer. The training-free variant uses greedy search to decide which layers keep an indexer, so no weight updates are needed. The training-aware variant trains the indexer with a multi-layer distillation loss. On a 30B model, it removes 75% of indexer computation and achieves 1.82× faster prefill and 1.48× faster decoding. Patches for SGLang and vLLM are also provided.
IndexCache: Accelerating Sparse Attention via Cross-Layer Index Reuse
Long-context agentic workflows have emerged as a defining use case for large language models, making attention efficiency critical for both inference speed and serving cost. Sparse attention...
https://arxiv.org/abs/2603.12201
KV Cache Transform Coding (KVTC)
This applies principles similar to JPEG compression to LLM memory, combining a pipeline of PCA-based feature decorrelation, adaptive quantization, and entropy coding. The PCA basis matrix is computed once on a calibration dataset and can then be reused for all subsequent inference.
KV Cache Transform Coding for Compact Storage in LLM Inference
Serving large language models (LLMs) at scale necessitates efficient key-value (KV) cache management. KV caches can be reused across conversation turns via shared-prefix prompts that are common in...
https://arxiv.org/abs/2511.01815