

 Seonglae Cho
Seonglae ChoUpdating Belief State and Belief State Geometry in Residual Stream
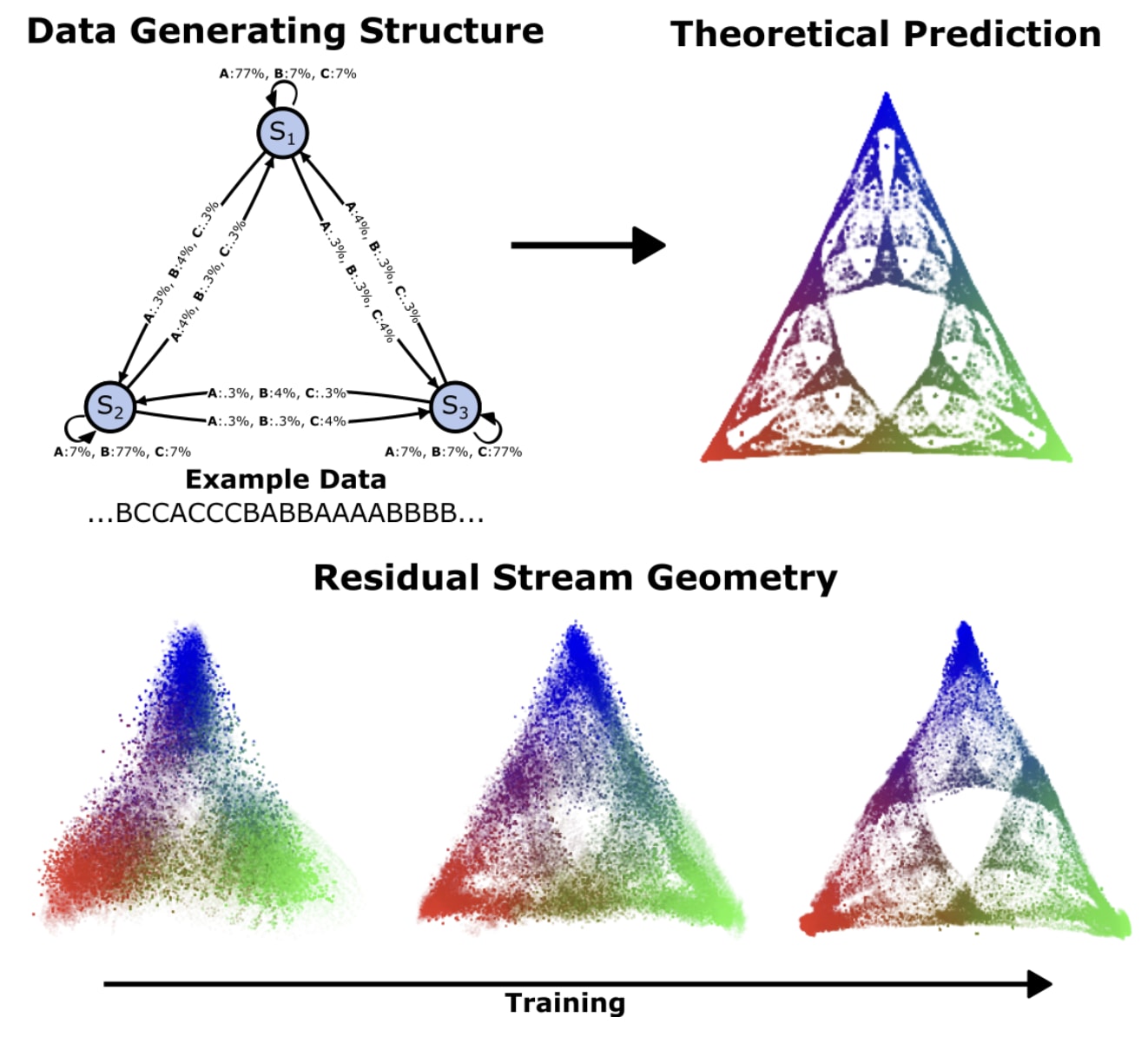
Data-generating is a Hidden Markov model where the hidden states are the belief states (world model) and the whole thing is Mixed-State Presentation (MSP). The Fractal structure of belief state (in this study, last layer of residual stream) geometry can be visualized with a vocabulary size of 3 using linear projections of the residual stream. When represented linearly using Barycentric Coordinate on a 2D simplex, we can observe that as tokens increase, LLMs synchronize to their internal world model as they move through the context window.
In their next study, the Simplex team connected theory and experiments focusing on the belief state geometry invoked by Next Token Prediction the computation performed by attention, the origins of In-context learning, and neural network computation models. If the probabilistic beliefs about hidden states in the data generation process are geometrically arranged as a simplex, then Constrained Belief Updating: attention can be decomposed spectrally (via transition matrix eigenvalues/eigenvectors) as a constrained Bayesian update using only past positional information. The essence of ICL is that due to non-Markov Property and non-Ergodicity properties (mixing of multiple sources), the model hierarchically infers "what the current source is + the state of that source." This naturally leads to a power-law decrease in loss with context length. Induction head can be interpreted as a solution for source discrimination, and similar phase transition signs were observed in RNNs as well.
In-context learning and Activation Steering are fundamentally the same mechanism. They both modify the model's Belief State about latent concepts. ICL accumulates evidence (likelihood) through contextual examples, while Steering directly shifts the prior probability. The two combine additively in log-belief space → small adjustments can cause sharp behavioral phase shifts. This perspective enables prediction and explanation of phenomena like many-shot ICL's sigmoid learning curve and jailbreak thresholds.
arxiv.org
https://arxiv.org/pdf/2511.00617
Transformers Represent Belief State Geometry in their Residual Stream — LessWrong
Produced while being an affiliate at PIBBSS[1]. The work was done initially with funding from a Lightspeed Grant, and then continued while at PIBBSS.…

https://www.lesswrong.com/posts/gTZ2SxesbHckJ3CkF/transformers-represent-belief-state-geometry-in-their
Simplex Progress Report - July 2025 — LessWrong
Thanks to Jasmina Urdshals, Xavier Poncini, and Justis Mills for comments. …
https://www.lesswrong.com/posts/fhkurwqhjZopx8DKK/simplex-progress-report-july-2025
Do Transformers represent the world in "parts"? Though trained only on token sequences, the real world may consist of multiple latent factors. Two possibilities exist: Joint representation, where all latent states are integrated into one space, or Factored representation, where each factor is represented in orthogonal subspaces. Experiments support the Factored World Hypothesis: when possible, the world is decomposed into factors, with each factor represented in orthogonal subspaces of the residual stream.
The data generation process is modeled as a GHMM (Generalized Hidden Markov Model). The predictive vector contains all information needed for the model to predict the future. The geometry of this predictive vector appears in transformer activations. Theoretical predictions: joint representation requires 242 dimensions, factored representation requires 10 dimensions. Experimental results → Transformers converge near 10 dimensions. Inductive bias experiments: tokens were mixed with noise to break conditional independence. Even so, early training → factored representation learned first, then dimensions expand as needed.
arxiv.org
https://arxiv.org/pdf/2602.02385