

 Seonglae Cho
Seonglae ChoModel diffing is a method for precisely comparing internal representations or functional differences between different neural networks (or different versions of the same model)
- Diffing models as a way to make safety auditing easier
General methods
- KL Divergence between token probability
Model Diffing Methods
2018
Chris Olah’s views on AGI safety — AI Alignment Forum
In thinking about AGI safety, I’ve found it useful to build a collection of different viewpoints from people that I respect, such that I can think fr…

https://www.alignmentforum.org/posts/X2i9dQQK3gETCyqh2/chris-olah-s-views-on-agi-safety

2022
arxiv.org
https://arxiv.org/pdf/2211.12491
CrossCoder (2024)
with Cross fine-tuning model & scaling transferability by diffing within same architecture
Sparse Crosscoders for Cross-Layer Features and Model Diffing
This note will cover some theoretical examples motivating crosscoders, and then present preliminary experiments applying them to cross-layer superposition and model diffing. We also briefly discuss the theory of how crosscoders might simplify circuit analysis, but leave results on this for a future update.
https://transformer-circuits.pub/2024/crosscoders/index.html
Open Source Replication of Anthropic’s Crosscoder paper for model-diffing — LessWrong
Intro Anthropic recently released an exciting mini-paper on crosscoders (Lindsey et al.). In this post, we open source a model-diffing crosscoder tra…

https://www.lesswrong.com/posts/srt6JXsRMtmqAJavD/open-source-replication-of-anthropic-s-crosscoder-paper-for
Stage-Wise Model Diffing
This work presents a novel approach to "model diffing" with dictionary learning that reveals how the features of a transformer change from finetuning. This approach takes an initial sparse autoencoder (SAE) dictionary trained on the transformer before it has been finetuned, and finetunes the dictionary itself on either the new finetuning dataset or the finetuned transformer model. By tracking how dictionary features evolve through the different fine-tunes, we can isolate the effects of both dataset and model changes.
https://transformer-circuits.pub/2024/model-diffing/index.html
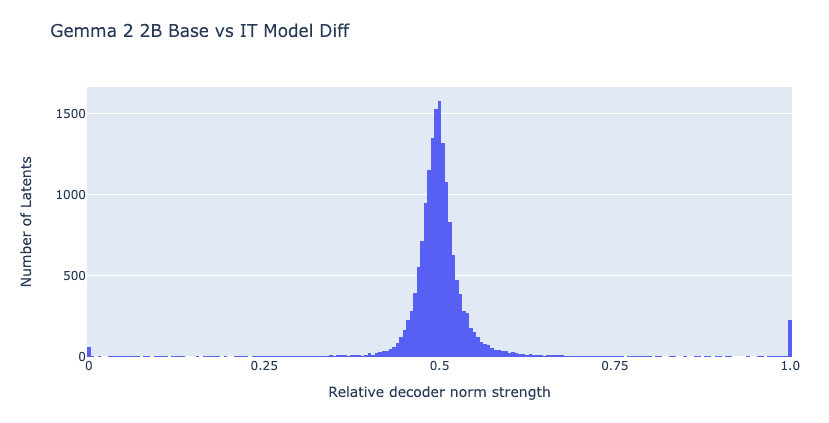
Using Crosscoder for chat Model Diffing reveals issues with traditional L1 sparsity approaches: many "chat-specific features" are falsely identified because they are actually existing concepts that shrink to zero in one model during training. Most chat-exclusive latents are training artifacts rather than genuine new capabilities.
Complete Shrinkage → A shared concept where one model's decoder shrinks to zero. Latent Decoupling → The same concept is represented by different latent combinations in two models.
Using Top-K (L0-style) sparsity instead of L1 reduces false positives and retains only alignment-related features. Chat tuning effects are primarily not about capabilities themselves, but rather: safety/refusal mechanisms, dialogue format processing, response length and summarization controls, and template token-based control. In other words, it acts more like a shallow layer that steers existing capabilities.
arxiv.org
https://arxiv.org/pdf/2504.02922