Seonglae Cho
Seonglae ChoSAE Feature Density often refers non-zero ratio
feature density of each feature is the fraction of tokens on which the feature has a nonzero value.
almost all of the features in the high density cluster are interpretable, but almost none of the features in the ultralow density cluster are.



Problems about density
- High frequency features which are common in Top-k, JumpReLU SAEs activates on 10% of input tokens. Their dynamics and semantics are unknown until now.
feature density histogram
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning
Mechanistic interpretability seeks to understand neural networks by breaking them into components that are more easily understood than the whole. By understanding the function of each component, and how they interact, we hope to be able to reason about the behavior of the entire network. The first step in that program is to identify the correct components to analyze.
https://transformer-circuits.pub/2023/monosemantic-features#appendix-feature-density
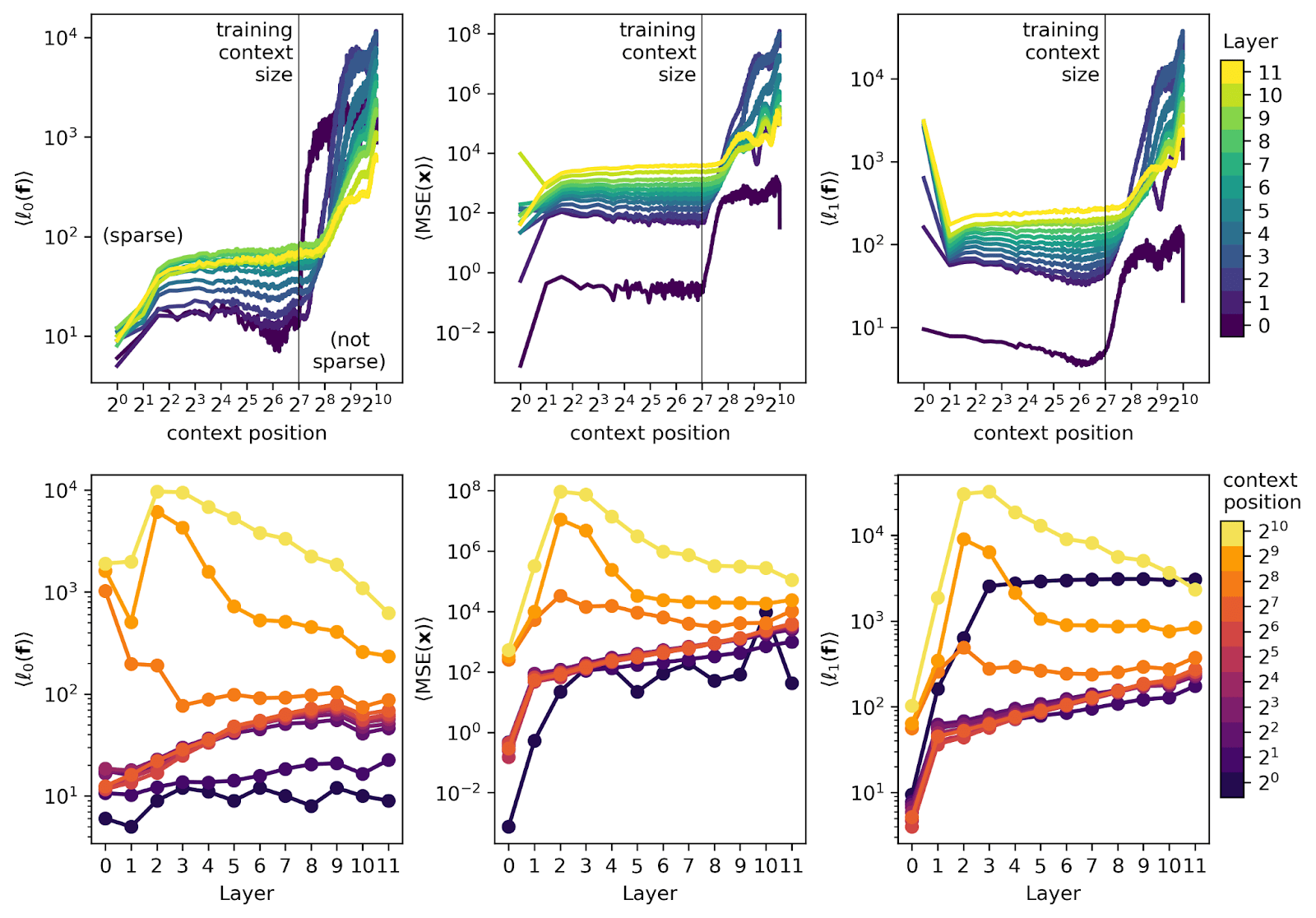
Layer wise visualized analysis
- SAE's reconstruction performance degrades sharply when exceeding the training context length
- In short contexts, performance worsens in later layers, while in long contexts, early layers show degraded performance
- While most SAE feature steering negatively impacts model performance, some features lead to improvements
- Errors in early layer SAEs negatively affect the performance of later layers
Examining Language Model Performance with Reconstructed Activations using Sparse Autoencoders — LessWrong
Note: The second figure in this post originally contained a bug pointed out by @LawrenceC, which has since been fixed. …

https://www.lesswrong.com/posts/8QRH8wKcnKGhpAu2o/examining-language-model-performance-with-reconstructed