

 Seonglae Cho
Seonglae ChoUMAP
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet
We find a diversity of highly abstract features. They both respond to and behaviorally cause abstract behaviors. Examples of features we find include features for famous people, features for countries and cities, and features tracking type signatures in code. Many features are multilingual (responding to the same concept across languages) and multimodal (responding to the same concept in both text and images), as well as encompassing both abstract and concrete instantiations of the same idea (such as code with security vulnerabilities, and abstract discussion of security vulnerabilities).
https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html#feature-survey-neighborhoods
Browsing code error feature
Feature UMAP
https://transformer-circuits.pub/2024/scaling-monosemanticity/umap.html?targetId=1m_1013764
Layer wise visualized analysis
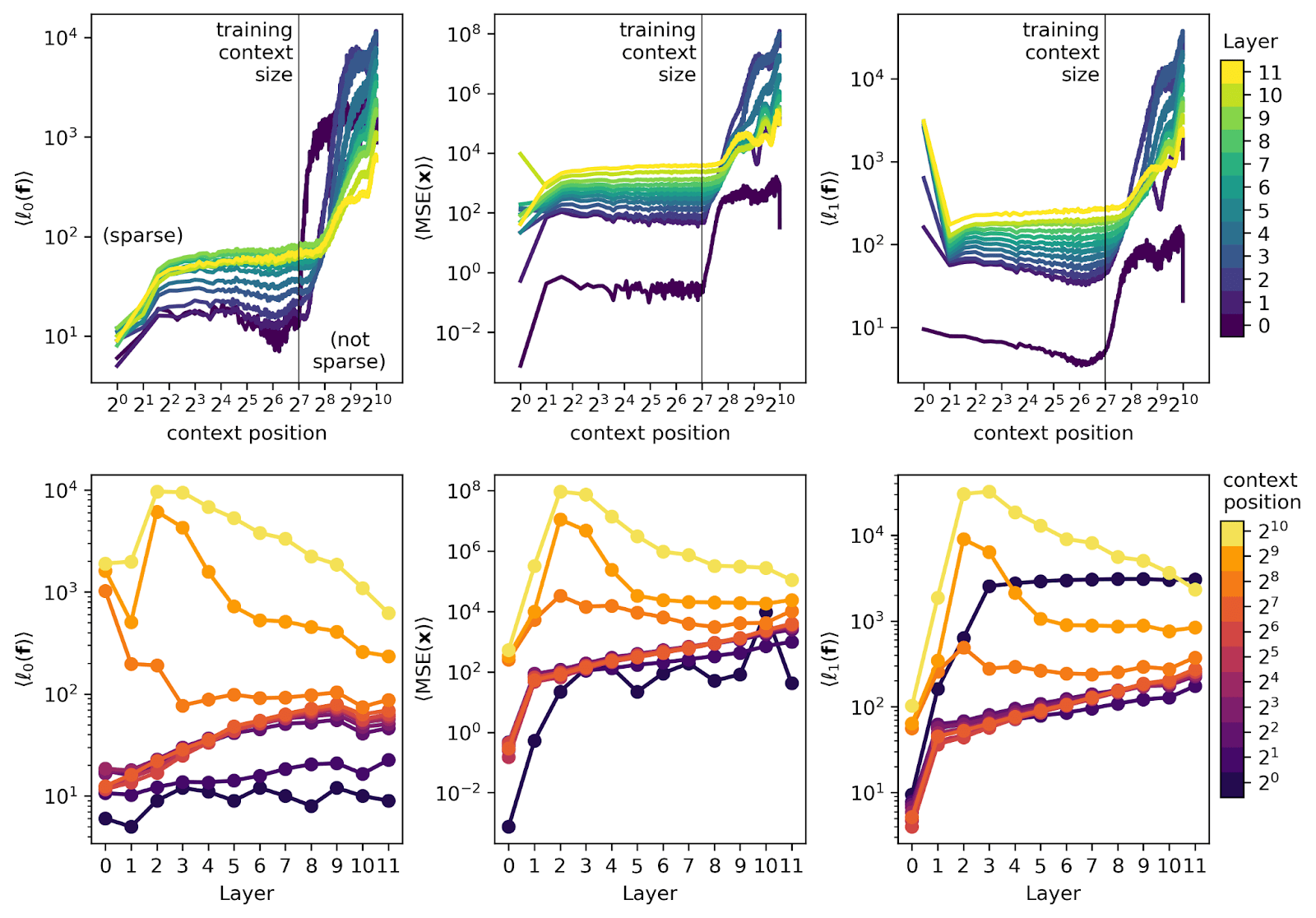
- SAE's reconstruction performance degrades sharply when exceeding the training context length
- In short contexts, performance worsens in later layers, while in long contexts, early layers show degraded performance
- While most SAE feature steering negatively impacts model performance, some features lead to improvements
- Errors in early layer SAEs negatively affect the performance of later layers
Examining Language Model Performance with Reconstructed Activations using Sparse Autoencoders — LessWrong
Note: The second figure in this post originally contained a bug pointed out by @LawrenceC, which has since been fixed. …

https://www.lesswrong.com/posts/8QRH8wKcnKGhpAu2o/examining-language-model-performance-with-reconstructed
Cos sim
When SAEs are scaled up (with more latents), "feature splitting" occurs (e.g., "math" → "algebra/geometry"), but this isn't always a good decomposition. While there appear to be monosemantic latents like "starts with S," in practice they suddenly fail to activate in certain cases (false negatives), and instead more specific child/token-aligned latents absorb that directional component and explain the model's behavior.
For features that fire independently, SAEs recover them well, but when hierarchical co-occurrence is introduced (e.g., "feature1 only appears when feature0 is present"), absorption occurs where the encoder creates gaps (parent latent turns off in certain situations). Generally, the more sparse and wider the SAE, the greater the tendency for absorption.
arxiv.org
https://arxiv.org/pdf/2409.14507
[Paper] A is for Absorption: Studying Feature Splitting and Absorption in Sparse Autoencoders — LessWrong
This research was completed for London AI Safety Research (LASR) Labs 2024. The team was supervised by Joseph Bloom (Decode Research). Find out more…
https://www.lesswrong.com/posts/3zBsxeZzd3cvuueMJ/paper-a-is-for-absorption-studying-feature-splitting-and
![[Paper] A is for Absorption: Studying Feature Splitting and Absorption in Sparse Autoencoders — LessWrong](https://res.cloudinary.com/lesswrong-2-0/image/upload/f_auto,q_auto/v1/mirroredImages/3zBsxeZzd3cvuueMJ/zqm9y76hakengraftq3q)