

 Seonglae Cho
Seonglae ChoSAE Transferability
SAEs (usually) Transferability Between Base and Chat Models
SAEs (usually) Transfer Between Base and Chat Models — LessWrong
This is an interim report sharing preliminary results that we are currently building on. We hope this update will be useful to related research occur…

https://www.lesswrong.com/posts/fmwk6qxrpW8d4jvbd/saes-usually-transfer-between-base-and-chat-models
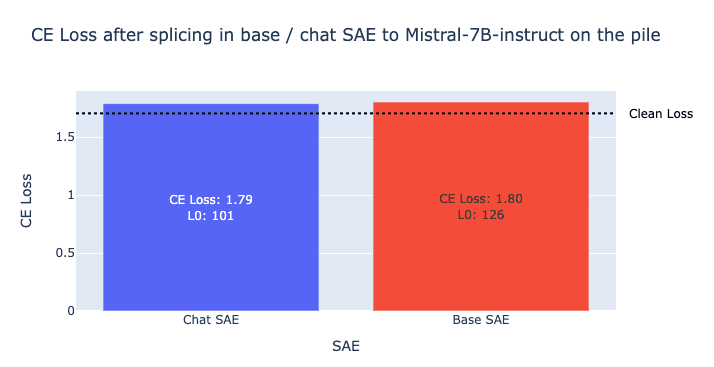
Do Sparse Autoencoders (SAEs) transfer across base and finetuned language models? — LessWrong
This is a project submission post for the AI Safety Fundamentals course from BlueDot Impact. Therefore, some of its sections are intended to be begin…
https://www.lesswrong.com/posts/bsXPTiAhhwt5nwBW3/do-sparse-autoencoders-saes-transfer-across-base-and

SAE analysis with fine tuning multimodal model (2025)
Analyzing Fine-tuning Representation Shift for Multimodal LLMs Steering
Multimodal LLMs have reached remarkable levels of proficiency in understanding multimodal inputs, driving extensive research to develop increasingly powerful models. However, much less attention has been paid to understanding and explaining the underlying mechanisms of these models. Most existing explainability research examines these models only in their final states, overlooking the dynamic representational shifts that occur during training. In this work, we systematically analyze the evolution of hidden state representations to reveal how fine-tuning alters the internal structure of a model to specialize in new multimodal tasks. Using a concept-based approach, we map hidden states to interpretable visual and textual concepts, enabling us to trace changes in encoded concepts across modalities as training progresses. We also demonstrate the use of shift vectors to capture these concepts changes. These shift vectors allow us to recover fine-tuned concepts by shifting those in the original model. Finally, we explore the practical impact of our findings on model steering, showing that we can adjust multimodal LLMs behaviors without any training, such as modifying answer types, captions style, or biasing the model toward specific responses. Our work sheds light on how multimodal representations evolve through fine-tuning and offers a new perspective for interpreting model adaptation in multimodal tasks.
The code for this project is publicly available at https://github.com/mshukor/xl-vlms.
https://arxiv.org/html/2501.03012v1
Using Jigsaw Toxic Comment dataset, token-wise toxicity signals were extracted from value vectors in GPT2-medium's MLP blocks, and the toxicity representation space was decomposed through SVD. After DPO training analysis, it was found that the model learned offsets to bypass toxic vector activation regions. However, toxic outputs can still be reproduced with minor adjustments.
A Mechanistic Understanding of Alignment Algorithms: A Case Study on DPO and Toxicity
HTML conversions sometimes display errors due to content that did not convert correctly from the source. This paper uses the following packages that are not yet supported by the HTML conversion tool. Feedback on these issues are not necessary; they are known and are being worked on.
https://arxiv.org/html/2401.01967v1
BatchTopK crosscoder to prevent Complete Shrinkage and Latent Decoupling for chat model
Robustly identifying concepts introduced during chat fine-tuning...
Model diffing is the study of how fine-tuning changes a model's representations and internal algorithms. Many behaviours of interest are introduced during fine-tuning, and model diffing offers a...
https://arxiv.org/abs/2504.02922
Fraction of variance unexplained when using SAEs trained on Gemma 2 2B PT to reconstruct the activations generated with Gemma 2 2B IT on user prompts.
arxiv.org
https://arxiv.org/pdf/2408.05147