Seonglae Cho
Seonglae ChoFeature Absorption reduces interpretability
Exploring SAE hierarchy is very important and valuable
When an SAE learns two separate features describing the same ground-truth feature, representations of that feature are split between the two learned features randomly.
Although the SAE appears to track a specific interpretable feature, in reality, it creates gaps in predictions and other unrelated latent variables absorb that feature
It seems to be an issue that occurs due to decomposing too sparsely
For example, the interpretable feature 'starts with L' is not activated under certain conditions, and instead, latent variables related to specific tokens like 'lion' absorb that direction.
It was discovered that sharing weights between the SAE encoder and decoder reduces Feature Absorption
Cos sim
When SAEs are scaled up (with more latents), "feature splitting" occurs (e.g., "math" → "algebra/geometry"), but this isn't always a good decomposition. While there appear to be monosemantic latents like "starts with S," in practice they suddenly fail to activate in certain cases (false negatives), and instead more specific child/token-aligned latents absorb that directional component and explain the model's behavior.
For features that fire independently, SAEs recover them well, but when hierarchical co-occurrence is introduced (e.g., "feature1 only appears when feature0 is present"), absorption occurs where the encoder creates gaps (parent latent turns off in certain situations). Generally, the more sparse and wider the SAE, the greater the tendency for absorption.
arxiv.org
https://arxiv.org/pdf/2409.14507
[Paper] A is for Absorption: Studying Feature Splitting and Absorption in Sparse Autoencoders — LessWrong
This research was completed for London AI Safety Research (LASR) Labs 2024. The team was supervised by Joseph Bloom (Decode Research). Find out more…
![[Paper] A is for Absorption: Studying Feature Splitting and Absorption in Sparse Autoencoders — LessWrong](https://res.cloudinary.com/lesswrong-2-0/image/upload/v1497915096/favicon_lncumn.ico)
https://www.lesswrong.com/posts/3zBsxeZzd3cvuueMJ/paper-a-is-for-absorption-studying-feature-splitting-and
![[Paper] A is for Absorption: Studying Feature Splitting and Absorption in Sparse Autoencoders — LessWrong](https://res.cloudinary.com/lesswrong-2-0/image/upload/f_auto,q_auto/v1/mirroredImages/3zBsxeZzd3cvuueMJ/zqm9y76hakengraftq3q)
Toy Models of Feature Absorption in SAEs — LessWrong
TLDR; In previous work, we found a problematic form of feature splitting called "feature absorption" when analyzing Gemma Scope SAEs. We hypothesized…
https://www.lesswrong.com/posts/kcg58WhRxFA9hv9vN/toy-models-of-feature-absorption-in-saes
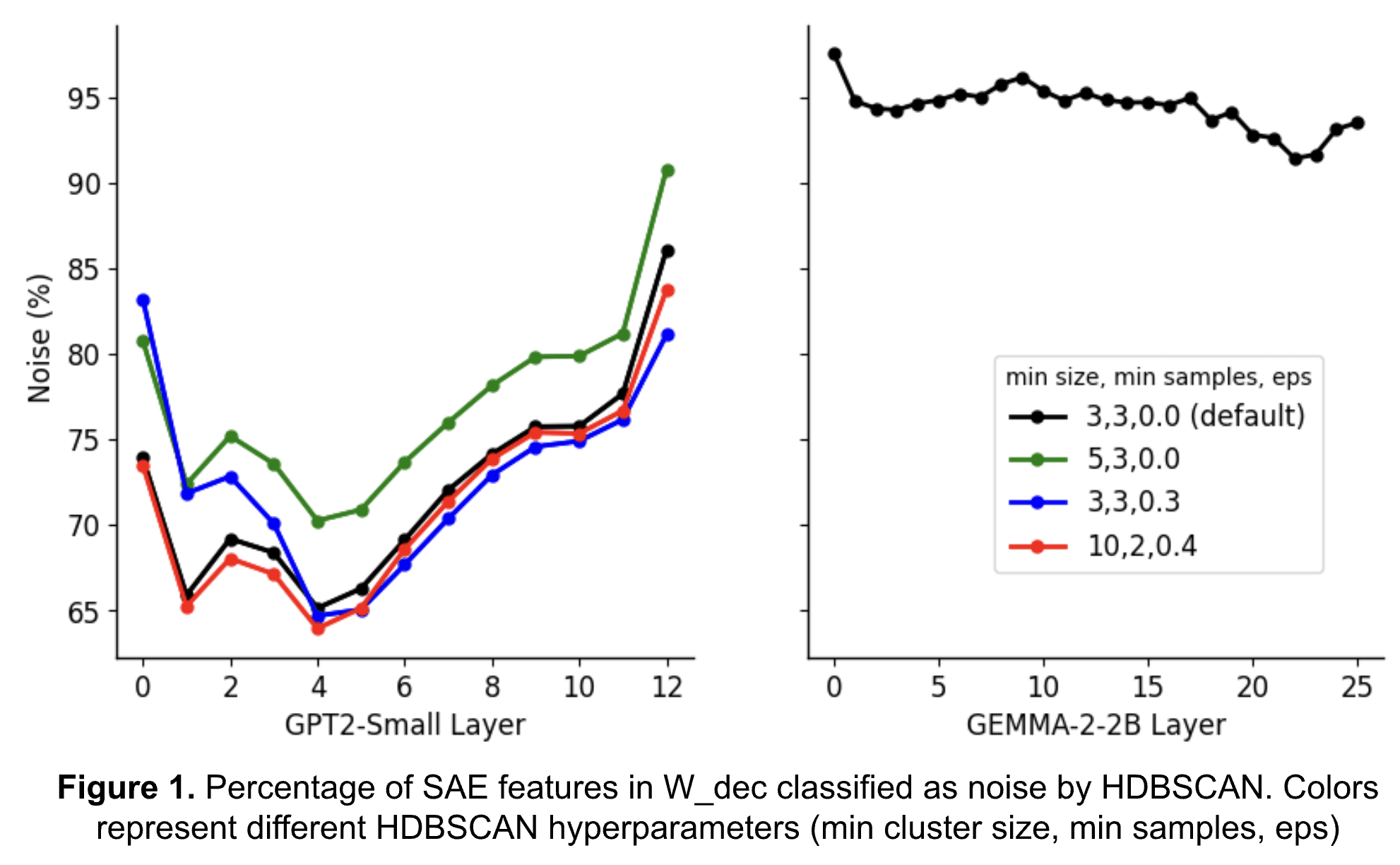
Clustering HDBSCAN
HDBSCAN is Surprisingly Effective at Finding Interpretable Clusters of the SAE Decoder Matrix — LessWrong
*All authors have equal contribution. • This is a short informal post about recent discoveries our team made when we: …
https://www.lesswrong.com/posts/Dc2w5kHXksSBcjNTs/hdbscan-is-surprisingly-effective-at-finding-interpretable
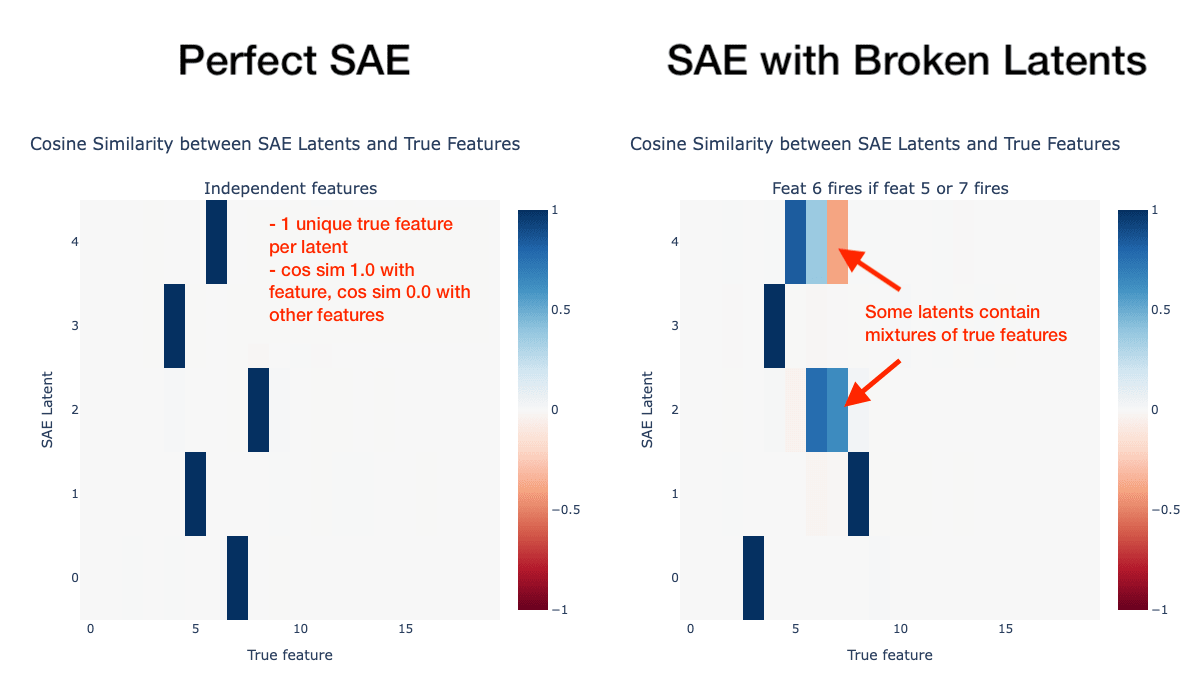
The SAE Feature Absorption and co-occurrence problems cause the model to learn "broken latents". While tied SAEs have cleaner representations due to identical encoder and decoder weights, issues still arise when there are insufficient latents for concepts like parent-child relationships.
To mitigate this mixing phenomenon, an auxiliary loss function (squared cosine similarity between inputs and feature directions at low activation states) is introduced to encourage single peaks in activation strength.
Broken Latents: Studying SAEs and Feature Co-occurrence in Toy Models — LessWrong
Thanks to Jean Kaddour, Tomáš Dulka, and Joseph Bloom for providing feedback on earlier drafts of this post. …
https://www.lesswrong.com/posts/XHpta8X85TzugNNn2/broken-latents-studying-saes-and-feature-co-occurrence-in