

 Seonglae Cho
Seonglae ChoExploring SAE hierarchy is very important and valuable

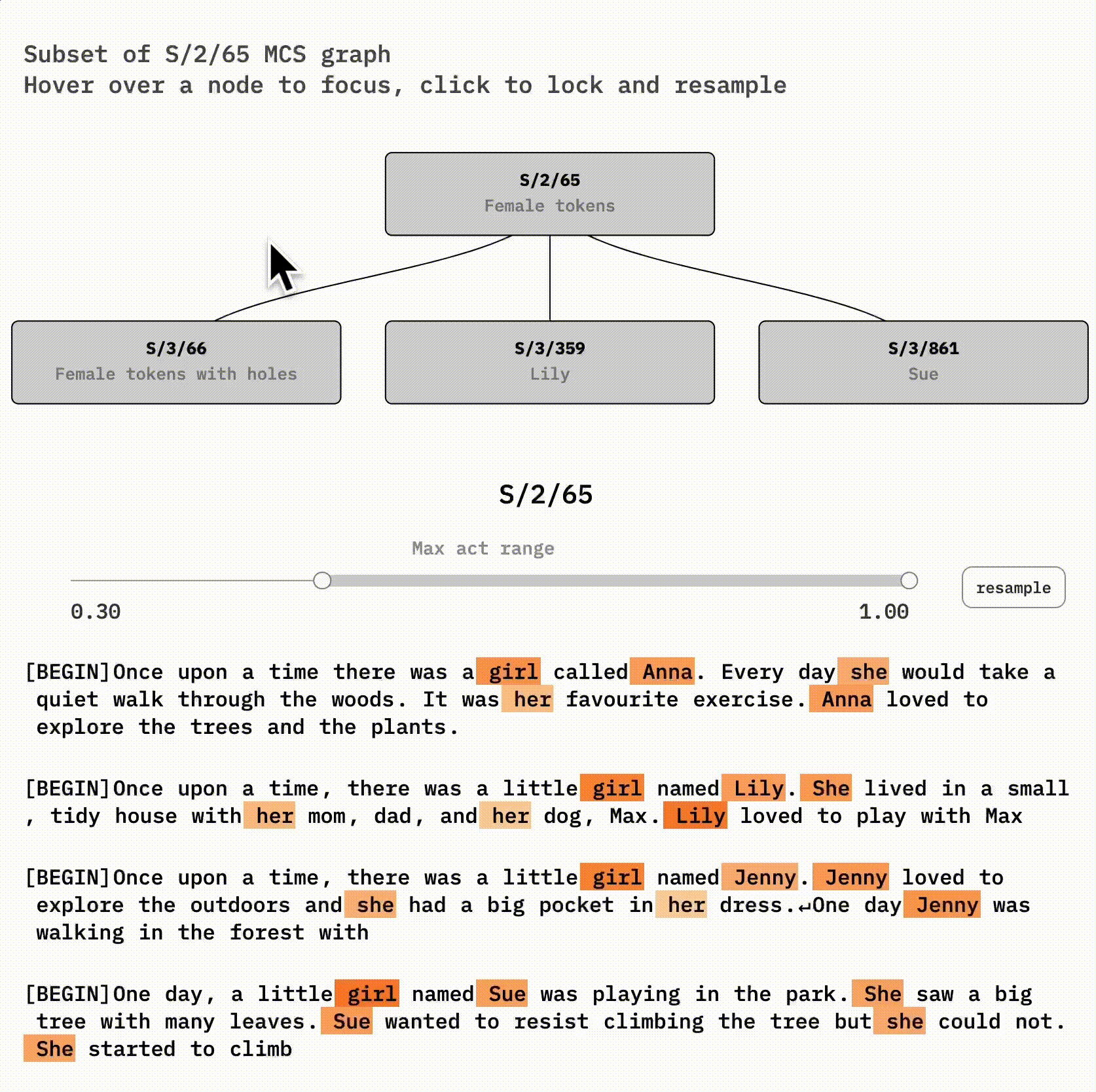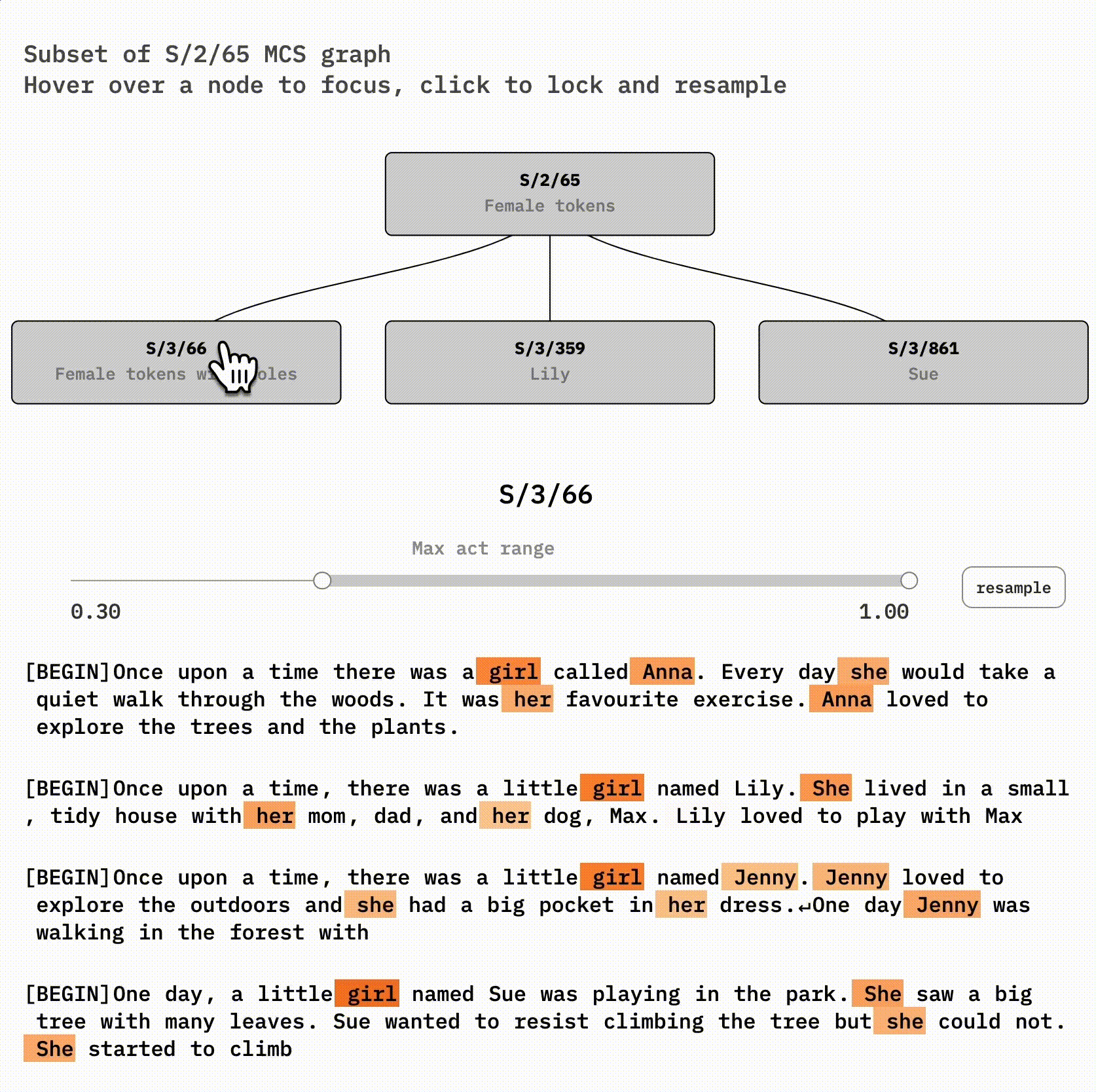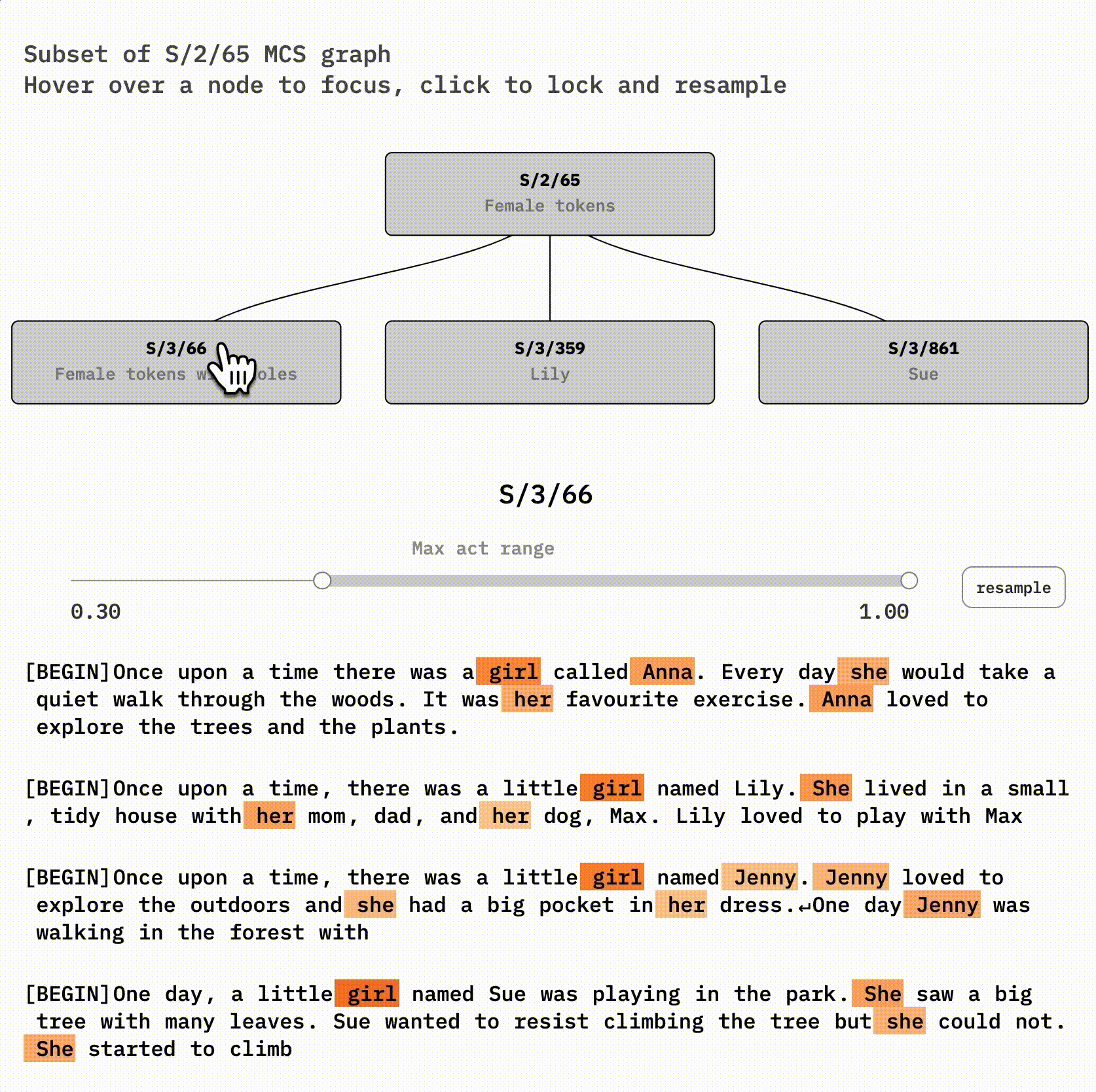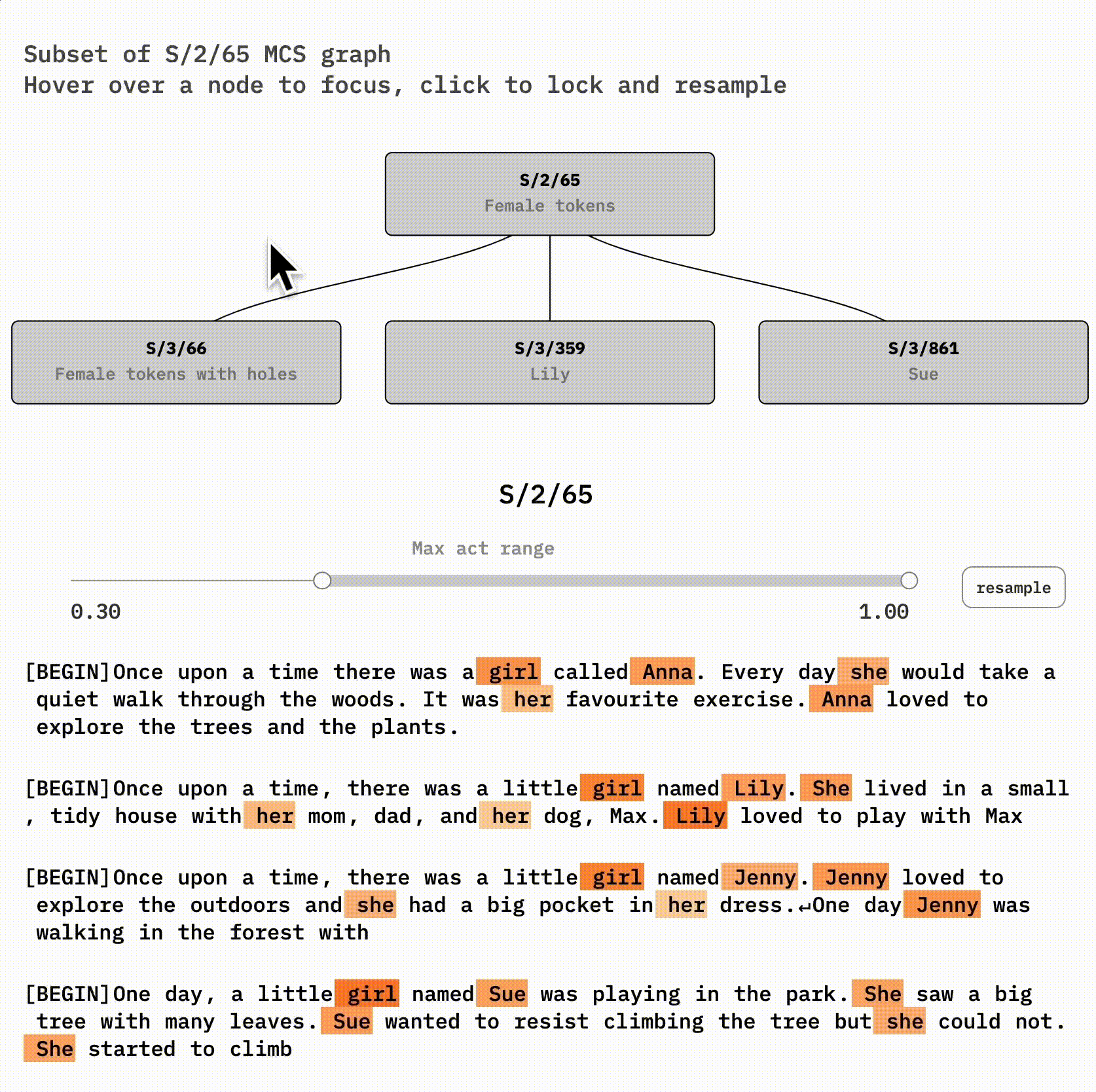
Feature Fragmentation

Split features were identified through masked cosine similarity between decoded neuron activations. The structure of this refinement is more complex than a tree: rather, the features we find at one level may both split and merge to form refined features at the next.
SAE Feature Splitting
There might some idealized set of features that dictionary learning would return if we provided it with an unlimited dictionary size. (true features). However correct number of features for dictionary learning is less important than it might initially seem. The fact that true features are clustered into sets of similar features suggests that dictionary learning with fewer features can provide a "summary" of model features.
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning
Mechanistic interpretability seeks to understand neural networks by breaking them into components that are more easily understood than the whole. By understanding the function of each component, and how they interact, we hope to be able to reason about the behavior of the entire network. The first step in that program is to identify the correct components to analyze.
https://transformer-circuits.pub/2023/monosemantic-features#phenomenology-feature-splitting
feature fragmentation
www.lesswrong.com
View trees here Search through latents with a token-regex language View individual latents here See code here (github.com/noanabeshima/matryoshka-sae…

https://www.lesswrong.com/posts/zbebxYCqsryPALh8C/matryoshka-sparse-autoencoders
For embedding
openreview.net
https://openreview.net/pdf?id=hjROYyfxfO
Cos sim
When SAEs are scaled up (with more latents), "feature splitting" occurs (e.g., "math" → "algebra/geometry"), but this isn't always a good decomposition. While there appear to be monosemantic latents like "starts with S," in practice they suddenly fail to activate in certain cases (false negatives), and instead more specific child/token-aligned latents absorb that directional component and explain the model's behavior.
For features that fire independently, SAEs recover them well, but when hierarchical co-occurrence is introduced (e.g., "feature1 only appears when feature0 is present"), absorption occurs where the encoder creates gaps (parent latent turns off in certain situations). Generally, the more sparse and wider the SAE, the greater the tendency for absorption.
arxiv.org
https://arxiv.org/pdf/2409.14507
[Paper] A is for Absorption: Studying Feature Splitting and Absorption in Sparse Autoencoders — LessWrong
This research was completed for London AI Safety Research (LASR) Labs 2024. The team was supervised by Joseph Bloom (Decode Research). Find out more…
https://www.lesswrong.com/posts/3zBsxeZzd3cvuueMJ/paper-a-is-for-absorption-studying-feature-splitting-and
![[Paper] A is for Absorption: Studying Feature Splitting and Absorption in Sparse Autoencoders — LessWrong](https://res.cloudinary.com/lesswrong-2-0/image/upload/f_auto,q_auto/v1/mirroredImages/3zBsxeZzd3cvuueMJ/zqm9y76hakengraftq3q)
SAEs assume concepts are independent and stationary over time, but actual LM activations exhibit strong temporal correlations and non-stationarity. SAE's temporal independence and fixed sparsity assumptions lead to bottlenecks such as SAE Feature Splitting.
Temporal Feature Analysis (TFA) decomposes activations into predictable (slow, contextual) components and novel (fast, residual) components. It outperforms SAE in garden-path sentence parsing, event boundary detection, and capturing long-range structure. In other words, interpretability tools require Inductive Bias aligned with the temporal structure of the data.
arxiv.org
https://arxiv.org/pdf/2511.01836