

 Seonglae Cho
Seonglae ChoComputational subgraph of a neural network.
In high level, Circuits are collections of features connected by weights that implements algorithms (Chris Olah)
The limitation of circuitry analysis is that it tends to focus only on single circuits or individual mechanisms, and in the case of attention, because it operates as an additive mechanism independently for each head, it is difficult to explain all complex mechanisms through interactions between heads alone. Therefore, the trend is moving towards independent functions of attention heads or SAEs themselves rather than circuits.
AI Circuit Notion
2020 Zoom in
Zoom In: An Introduction to Circuits
By studying the connections between neurons, we can find meaningful algorithms in the weights of neural networks.
https://distill.pub/2020/circuits/zoom-in/
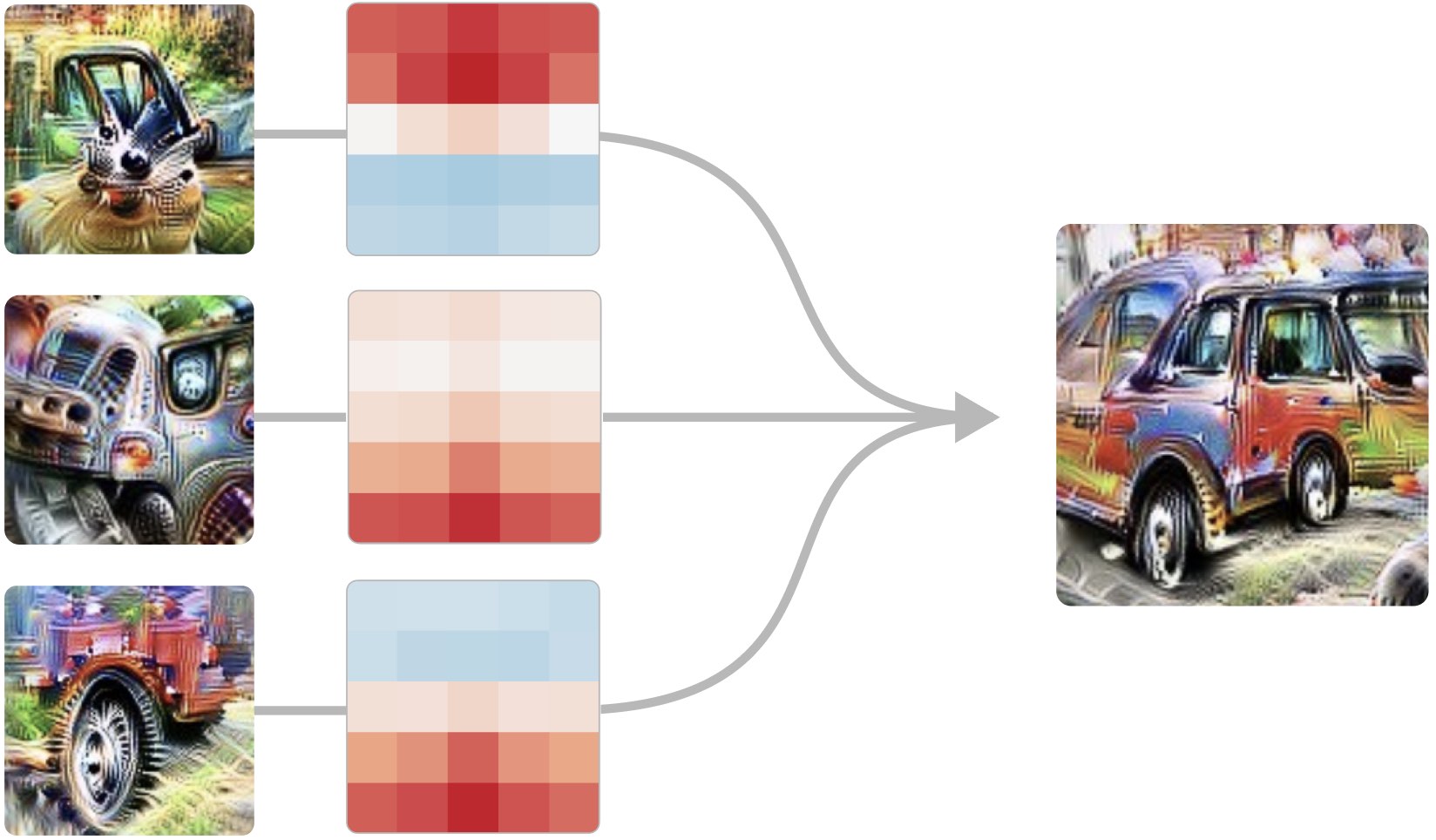
Isolating circuit paths
Circuits Updates - April 2024
We report a number of developing ideas on the Anthropic interpretability team, which might be of interest to researchers working actively in this space. Some of these are emerging strands of research where we expect to publish more on in the coming months. Others are minor points we wish to share, since we're unlikely to ever write a paper about them.
https://transformer-circuits.pub/2024/april-update/index.html#circuit-path-lengths
society of thought
Reasoning Model shows that the perspective of models simulating an internal structure where multiple viewpoints interact has more explanatory power than the conventional view that attributes improved model performance to "longer chain-of-thought." Experimental results demonstrate that even when only rewarding correct answers, models spontaneously develop conversational behaviors (such as questioning and perspective shifts), and using conversational scaffolding in fine-tuning leads to faster improvements in reasoning performance.
arxiv.org
https://arxiv.org/pdf/2601.10825
Marr framework: Multilevel computational algorithmic implementation
arxiv.org
https://arxiv.org/pdf/2408.12664
Training selects behaviors, not internal circuitry; therefore, there can be many different weight configurations that implement the same function.
ACE (Algorithmic Core Extraction) extracts an algorithmic-core subspace by identifying directions in the hidden state that are both active (high input variance) and relevant (sensitive in the output). Active directions come from the covariance of the hidden activation matrix , and relevant directions come from the Jacobian. This yields a minimal-dimensional subspace that is both necessary and sufficient.
Under weight decay, the minimum-norm solution can be formulated as a constrained optimization problem: minimize the norm over all mode amplitudes subject to satisfying a margin constraint. By the Cauchy–Schwarz inequality, activating all modes is optimal, and weight decay acts as a force for redistribution rather than simplification. Grokking delay can be derived from the dynamics of the margin trajectory, and under high redundancy it follows an inverse scaling law: grokking time is inversely proportional to weight decay and functional redundancy. This framework is inspired by the Kalman decomposition from control theory, empirically applying the notion of minimal realization of linear systems to transformers.
arxiv.org
https://arxiv.org/pdf/2602.22600